
For the vast majority of sports bettors, placing a wager is an act of intuition. It is a decision driven by narrative, fandom, or a "gut feeling" derived from watching the last few games. While this approach can occasionally yield wins, it is mathematically impossible to beat the sportsbooks long-term using intuition alone. The house edge, or "vig," is designed to grind down subjective decision-making over time.
To transition from a recreational gambler to a profitable sharp, you must stop guessing and start calculating. This means moving away from betting on teams and starting to bet on numbers.
This guide introduces the world of predictive modeling. We will strip away the reliance on media narratives and focus on building a quantitative engine that outputs its own betting lines. By comparing your model's "true odds" against the odds offered by crypto sportsbooks, you can identify positive Expected Value (+EV) and secure a mathematical edge.

The Philosophy of the Model: Price vs. Outcome
Before opening Excel or writing a line of Python code, you must shift your mindset regarding the objective of betting.
A common novice mistake is asking, "Who will win the game?" A predictive model does not answer that question directly. Instead, it answers: "What is the probability of this team winning?"
If your model determines that the Kansas City Chiefs have a 60% chance of winning, but the sportsbook's odds imply a 70% chance, you do not bet on the Chiefs, even if you think they will win. Conversely, if the sportsbook implies a 40% chance, the Chiefs become a massive value bet.
Why Data-Driven Betting Works
Sportsbooks are efficient, but they are not perfect. They have to balance their books to mitigate risk, often shading lines based on public perception. A robust model exploits these inefficiencies.
- Objectivity: Models ignore hype. They don't care if a star player is "due" for a big game unless the data supports it.
- Scalability: A human can analyze three games deeply in an hour. A model can analyze 300 games in three seconds.
- Discipline: Models provide a rigid framework for staking, preventing the emotional tilt that destroys bankrolls.
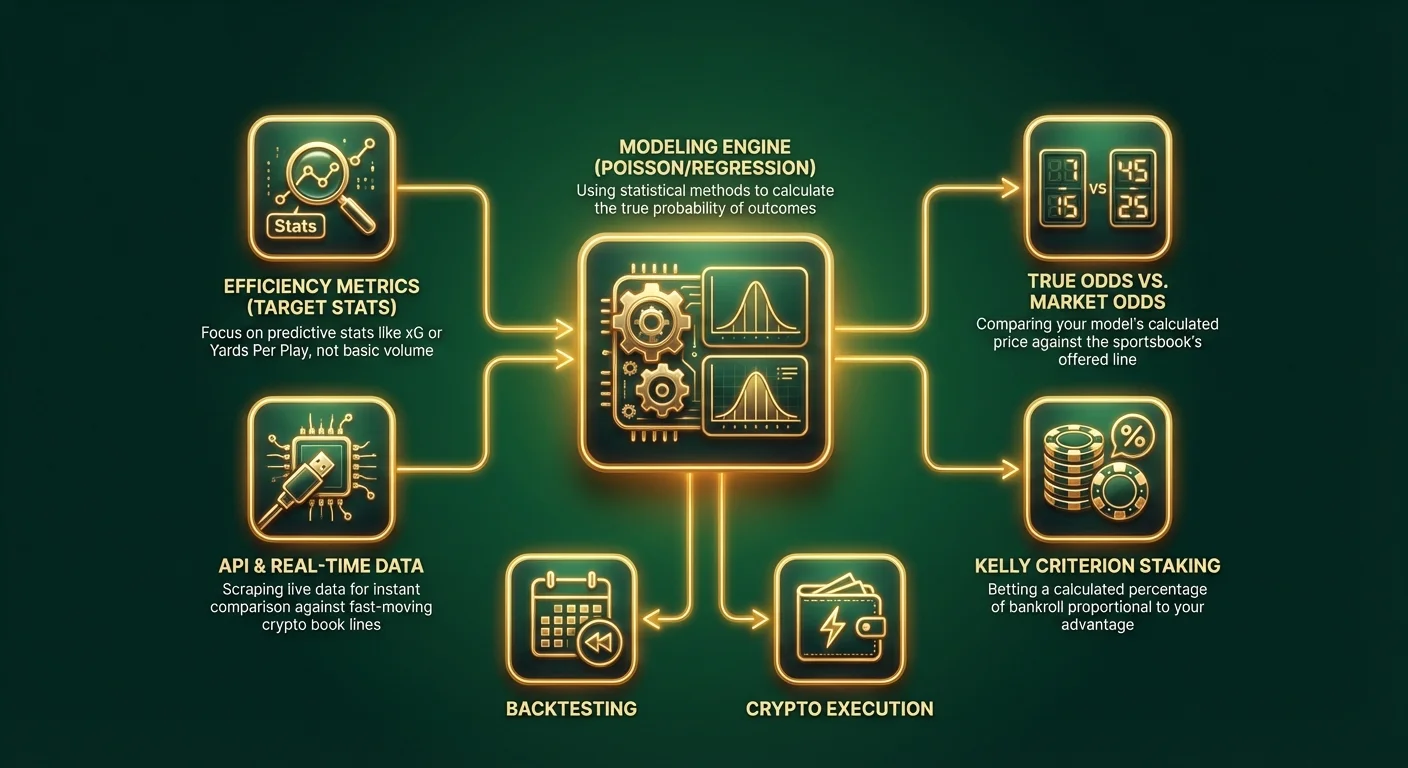
Step 1: Defining the Scope and Variable Selection
Don't try to build a "Sports Betting Model" that covers everything. Start small. Pick one sport and one specific market.
Recommended Starting Points:
- NBA Totals: High volume of scoring events reduces variance compared to low-scoring sports.
- NFL Spreads: Highly liquid markets, though very efficient (hard to beat).
- Soccer 1X2 (Moneyline): Great for statistical modeling due to the Poisson distribution nature of goal scoring.
Feature Engineering (Selecting Your Metrics)
Garbage in, garbage out. The quality of your model depends entirely on the data you feed it. Avoid basic stats like "Wins/Losses" or "Points Per Game," as these are already baked into every line. Look for predictive metrics - stats that correlate strongly with future performance.
| Sport | Basic Stat (Avoid) | Advanced Stat (Target) | Why? |
|---|---|---|---|
| NBA | Points Per Game | Offensive Efficiency (ORtg) / Pace | Accounts for the speed of the game; a fast team scores more but isn't necessarily better. |
| NFL | Total Yards | Yards Per Play / DVOA | Volume stats are misleading; efficiency per snap predicts future success better. |
| Soccer | Goals Scored | Expected Goals (xG) | xG measures the quality of chances created, which is more predictive than lucky finishes. |
| MLB | Pitcher Wins | FIP (Fielding Independent Pitching) | Isolates the pitcher's performance from the defense behind him. |
Pro Tip: If you are betting with Bitcoin or stablecoins on modern crypto sportsbooks, you often have access to API integrations. Savvy bettors use scripts to scrape real-time data and compare it instantly against the odds on fast-moving crypto platforms.
Step 2: Choosing Your Modeling Method
There are three primary entry-level methods for building a predictive model.
1. The Power Ranking Model (Simple)
This assigns a numerical rating to every team. The difference between the two ratings, plus an adjustment for home-field advantage, creates the spread.
- Example: Team A (Rating 105) vs. Team B (Rating 98) on a neutral field implies Team A is a 7-point favorite.
2. Regression Analysis (Intermediate)
This uses historical data to find correlations between variables and outcomes. You might run a linear regression to see how "Passing Yards per Attempt" and "Turnover Differential" correlate with the final point margin.
- Tool: Microsoft Excel (Data Analysis Toolpak) or Google Sheets.
3. Poisson Distribution (Advanced)
Ideal for low-scoring sports like Soccer or Hockey. It calculates the probability of a specific number of independent events (goals) happening within a fixed time.
- Concept: If a team averages 1.5 goals per game, Poisson math can tell you exactly how likely they are to score 0, 1, 2, or 3 goals in the next match.
Step 3: Building a Simple Poisson Model for Soccer
Let's walk through a practical example of building a model to predict a Premier League match using the Poisson Distribution. This can be done entirely in a spreadsheet.
Phase A: Calculate Attack and Defense Strength
You need to determine how much better or worse a team is compared to the league average.
- League Average: Calculate the average goals scored per game by a Home Team and an Away Team across the whole league. (e.g., Home Avg = 1.5, Away Avg = 1.2).
- Team Attack Strength: Divide a team's average goals scored by the League Average.
- Team Defense Strength: Divide a team's average goals conceded by the League Average.
Phase B: Predict Expected Goals (xG)
To find out how many goals Team A (Home) is likely to score against Team B (Away), use this formula:
- Example:
- Manchester City Attack Strength: 1.8 (Very strong)
- Chelsea Defense Strength: 0.9 (Better than average)
- League Avg Home Goals: 1.5
- Predicted City Goals:
Repeat this for the Away team to get their predicted goal total.
Phase C: Convert to Probabilities
Now that you have the predicted scores (e.g., City 2.43 - Chelsea 0.85), you use the Poisson function (available in Excel as =POISSON.DIST) to calculate the percentage chance of every specific scoreline (1-0, 2-0, 1-1, etc.).
Summing up all the scorelines where City wins gives you their Win Probability.
Step 4: Converting Probability to Odds
This is the most critical step in sports analytics. You must translate your percentage into a betting line to compare with the sportsbook.
The Formula:
The Comparison:
| Outcome | Your Model Probability | Your "True" Odds | Sportsbook Odds | Edge (EV) | Action |
|---|---|---|---|---|---|
| Man City Win | 65% | 1.54 | 1.45 | Negative | Pass |
| Draw | 20% | 5.00 | 4.50 | Negative | Pass |
| Chelsea Win | 15% | 6.67 | 8.00 | Positive | BET |
In this scenario, even if your model thinks City is the likely winner, the value is on Chelsea. The sportsbook is paying 8.00 (7/1) on an outcome your math says should be 6.67. Over thousands of bets, taking these value positions guarantees profit.
Step 5: Backtesting and Optimization
You have a model. Do not bet real money yet. You must perform Out-of-Sample Testing.
If you built your model using data from the 2020-2023 seasons, you cannot test it on those same seasons. Your model already "knows" those results. You must test it on the 2024 season (or a dataset it hasn't seen) to see if it actually predicts the future.
Common Modeling Pitfalls:
- Overfitting: Creating a model that perfectly explains the past but fails in the future because it relied on noise/coincidence rather than signal.
- Look-ahead Bias: Accidentally including data in your test that wouldn't have been available at the time of the game (e.g., using full-season stats to predict a Week 2 game).
- Ignoring Context: A model cannot read Twitter. It doesn't know the starting Quarterback has the flu. You must manually adjust for major lineup changes.
Execution: Staking and Crypto Advantages
Once your model is proven to have a positive ROI (Return on Investment) over a significant sample size (at least 500 bets), it is time to execute.
The Kelly Criterion
Don't flat bet. Use a staking strategy based on your edge. The Kelly Criterion suggests betting a percentage of your bankroll proportional to your advantage.
- Simplified Kelly: (Decimal Odds * Probability - 1) / (Decimal Odds - 1)
- Warning: Full Kelly is volatile. Most pros bet "Quarter Kelly" or "Half Kelly" to reduce variance.
Leveraging Crypto Sportsbooks
Quantitative betting requires efficiency. Crypto betting sites offer distinct advantages for model-based bettors:
- API Access: Many modern crypto books allow for automated betting via API, ensuring you catch the line the second your model identifies value.
- Higher Limits: Unlike soft fiat books that limit winners quickly, high-volume crypto exchanges and sharps often tolerate winning players because they help shape the market efficiency.
- Instant Settlement: When running a high-volume model, cash flow is king. Instant Bitcoin or USDT withdrawals mean you can cycle your bankroll faster, compounding your edge daily rather than weekly.
Practical Tips for Your First Model
- Start with "Toy" Models: Don't try to beat the NFL closing line immediately. Try to model something smaller, like 1st Quarter points or player props. These markets are less efficient.
- Track the "CLV": Closing Line Value is the gold standard of modeling. If you bet the Chiefs at -3 and the line closes at -4.5, your model is working, even if the Chiefs lose the game. Consistently beating the closing line is the surest indicator of long-term profitability.
- Learn Python or R: While Excel is great for learning, eventually, you will hit a wall with data processing. Python (with libraries like Pandas and Scikit-learn) is the industry standard for sports analytics.
- Scrape Your Own Data: Don't rely on averages found on websites. Build scrapers to get play-by-play data. The more granular your data, the more unique your edge.
Summary
Building a predictive model is not a get-rich-quick scheme. It is a data science project that requires patience, statistical literacy, and rigorous discipline.
- Define your goal: Pick a specific sport and market.
- Gather data: Focus on predictive efficiency metrics, not volume stats.
- Build the engine: Use Regression or Poisson distribution to calculate probabilities.
- Compare odds: Convert probabilities to prices and find discrepancies in the market.
- Backtest: Prove the model works on unseen data.
- Execute: Use crypto sportsbooks for the best odds and fast liquidity.
When you stop caring about which team wins and start caring about the difference between implied probability and true probability, you have officially graduated from a gambler to a sports investor.