
Для переважної більшості гравців на ставках розміщення парі є актом інтуїції. Це рішення, кероване розповіддю, фанатством або "внутрішнім відчуттям", що випливає з перегляду кількох останніх ігор. Хоча такий підхід може іноді приносити перемоги, математично неможливо обіграти букмекерські контори в довгостроковій перспективі, використовуючи лише інтуїцію. Перевага закладу, або "віг", створена для того, щоб з часом нівелювати суб'єктивне прийняття рішень.
Щоб перейти від любителя до прибуткового професіонала (sharp), ви повинні припинити вгадувати й почати розраховувати. Це означає відійти від ставок на команди і почати ставити на числа.
Цей посібник знайомить зі світом предиктивного моделювання. Ми відмовимося від опори на медіа-наративи та зосередимося на створенні кількісного механізму, який видає власні лінії ставок. Порівнюючи "справжні коефіцієнти" вашої моделі з коефіцієнтами, пропонованими криптобукмекерами, ви можете визначити позитивну Очікувану Цінність (+EV) та отримати математичну перевагу.

Філософія моделі: Ціна проти Результату
Перш ніж відкривати Excel або писати рядок коду Python, ви повинні змінити своє мислення щодо мети ставок.
Поширена помилка новачка полягає в запитанні: "Хто виграє гру?" Предиктивна модель не відповідає на це запитання безпосередньо. Натомість, вона відповідає: "Яка ймовірність перемоги цієї команди?"
Якщо ваша модель визначає, що Kansas City Chiefs мають 60% шансів на перемогу, але коефіцієнти букмекера передбачають 70% шансів, ви не ставите на Chiefs, навіть якщо вважаєте, що вони виграють. І навпаки, якщо букмекер передбачає 40% шансів, Chiefs стають надзвичайно цінною ставкою.
Чому ставки на основі даних працюють
Букмекерські контори ефективні, але не ідеальні. Вони повинні збалансувати свої книги, щоб мінімізувати ризики, часто коригуючи лінії на основі суспільного сприйняття. Надійна модель експлуатує ці неефективності.
- Об'єктивність: Моделі ігнорують хайп. Їм байдуже, чи має "вистрілити" зірковий гравець у великій грі, якщо дані це не підтверджують.
- Масштабованість: Людина може глибоко проаналізувати три гри за годину. Модель може проаналізувати 300 ігор за три секунди.
- Дисципліна: Моделі забезпечують жорстку основу для розміру ставок, запобігаючи емоційному тильту, який руйнує банкроли.
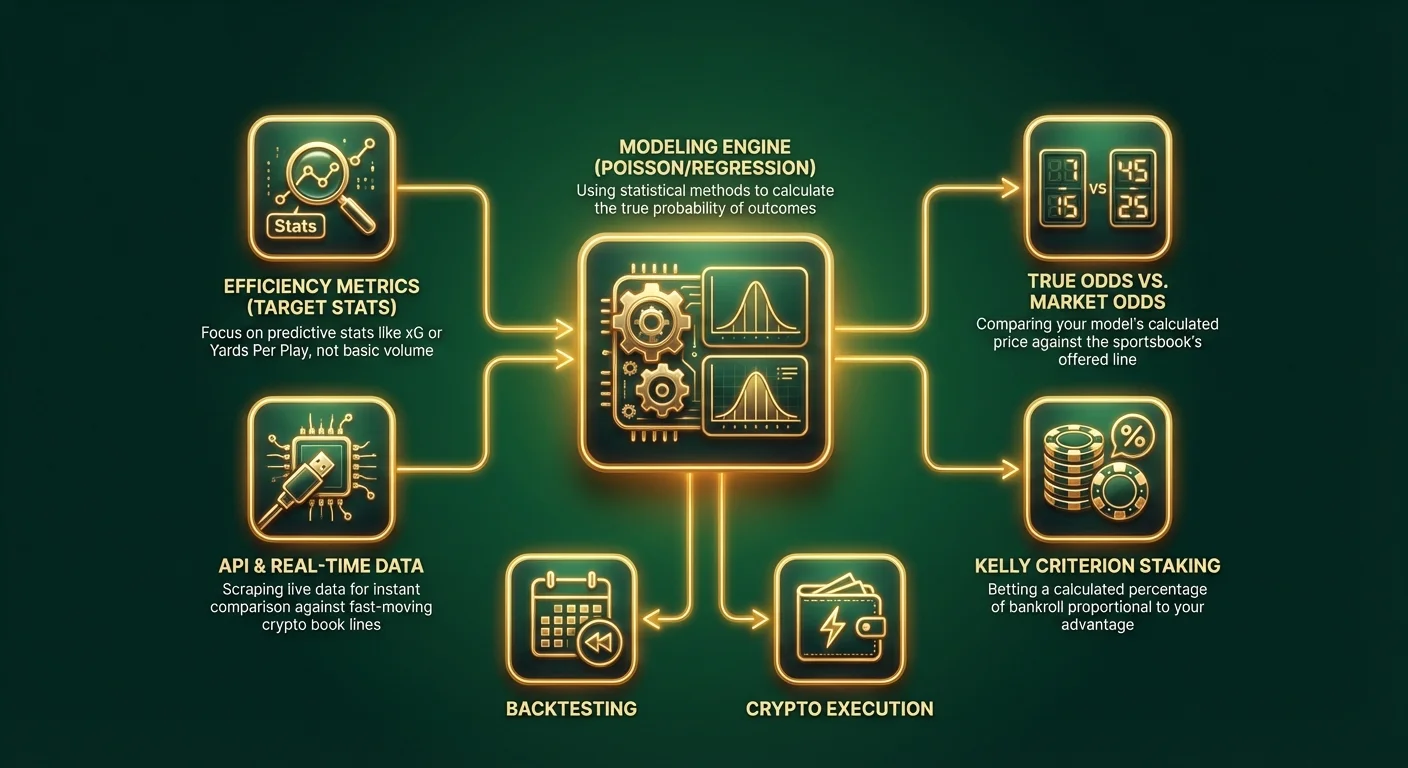
Крок 1: Визначення Обсягу та Вибір Змінних
Не намагайтеся створити "Модель Спортивних Ставок", яка охоплює все. Почніть з малого. Оберіть один вид спорту та один конкретний ринок.
Рекомендовані Відправні Точки:
- Тотали NBA: Високий обсяг забитих очок зменшує дисперсію порівняно з видами спорту з низькою результативністю.
- Спреди NFL: Високоліквідні ринки, хоча й дуже ефективні (їх важко обіграти).
- Футбол 1X2 (Moneyline): Чудово підходить для статистичного моделювання завдяки характеру розподілу Пуассона для забитих голів.
Feature Engineering (Вибір Ваших Метрик)
Сміття на вході, сміття на виході. Якість вашої моделі повністю залежить від даних, які ви їй надаєте. Уникайте базової статистики, як-от "Перемоги/Поразки" або "Очок за гру", оскільки вони вже враховані в кожній лінії. Шукайте предиктивні показники - статистику, яка сильно корелює з майбутньою продуктивністю.
| Спорт | Базова Статистика (Уникати) | Просунута Статистика (Мета) | Чому? |
|---|---|---|---|
| NBA | Очок за гру | Offensive Efficiency (ORtg) / Pace | Враховує швидкість гри; швидка команда забиває більше, але не обов'язково є кращою. |
| NFL | Загальна Кількість Ярдів | Yards Per Play / DVOA | Об'ємна статистика вводить в оману; ефективність на один розіграш краще прогнозує майбутній успіх. |
| Soccer | Забитих Голів | Expected Goals (xG) | xG вимірює якість створених моментів, що є більш предиктивним, ніж щасливі завершення. |
| MLB | Перемоги Пітчера | FIP (Fielding Independent Pitching) | Ізолює продуктивність пітчера від захисту позаду нього. |
Професійна Порада: Якщо ви робите ставки за допомогою Bitcoin або stablecoins на сучасних криптобукмекерських конторах, ви часто маєте доступ до інтеграцій API. Кмітливі гравці використовують скрипти для збору даних у реальному часі та миттєвого порівняння їх із коефіцієнтами на швидкоплинних криптоплатформах.
Крок 2: Вибір Методу Моделювання
Існує три основні методи початкового рівня для створення предиктивної моделі.
1. Модель Рейтингу Сили (Проста)
Це присвоєння числового рейтингу кожній команді. Різниця між двома рейтингами, плюс коригування на перевагу домашнього поля, створює спред.
- Приклад: Команда A (Рейтинг 105) проти Команди B (Рейтинг 98) на нейтральному полі передбачає, що Команда A є фаворитом з перевагою 7 очок.
2. Регресійний Аналіз (Середній рівень)
Це використання історичних даних для пошуку кореляцій між змінними та результатами. Ви можете запустити лінійну регресію, щоб побачити, як "Ярди Пасу на Спробу" та "Різниця Обертів" корелюють із кінцевим відривом у очках.
- Інструмент: Microsoft Excel (Data Analysis Toolpak) або Google Sheets.
3. Розподіл Пуассона (Просунутий)
Ідеально підходить для низькорезультативних видів спорту, таких як Футбол чи Хокей. Він обчислює ймовірність того, що певна кількість незалежних подій (голів) відбудеться протягом фіксованого часу.
- Концепція: Якщо команда в середньому забиває 1.5 голи за гру, математика Пуассона може точно сказати вам, наскільки ймовірно, що вони заб'ють 0, 1, 2 або 3 голи в наступному матчі.
Крок 3: Створення Простої Моделі Пуассона для Футболу
Розглянемо практичний приклад створення моделі для прогнозування матчу Прем'єр-ліги за допомогою Розподілу Пуассона. Це можна зробити повністю в електронній таблиці.
Фаза A: Розрахунок Сили Атаки та Захисту
Вам потрібно визначити, наскільки команда краща або гірша порівняно із середнім показником ліги.
- Середній Показник Ліги: Обчисліть середню кількість голів, забитих за гру Домашньою Командою та Командою На Виїзді по всій лізі. (наприклад, Середнє Домашнє = 1.5, Середнє Виїзне = 1.2).
- Сила Атаки Команди: Розділіть середню кількість голів, забитих командою, на Середній Показник Ліги.
- Сила Захисту Команди: Розділіть середню кількість пропущених голів командою на Середній Показник Ліги.
Фаза B: Прогнозування Очікуваних Голів (xG)
Щоб дізнатися, скільки голів Команда А (Вдома) ймовірно заб'є проти Команди В (На Виїзді), використовуйте цю формулу:
- Приклад:
- Сила Атаки Manchester City: 1.8 (Дуже сильна)
- Сила Захисту Chelsea: 0.9 (Краща за середню)
- Середня Кількість Домашніх Голів Ліги: 1.5
- Прогнозовані Голи City:
Повторіть це для команди На Виїзді, щоб отримати їхню прогнозовану загальну кількість голів.
Фаза C: Перетворення на Ймовірності
Тепер, коли у вас є прогнозовані результати (наприклад, City 2.43 - Chelsea 0.85), ви використовуєте функцію Пуассона (доступну в Excel як =POISSON.DIST) для обчислення відсоткової ймовірності кожного конкретного рахунку (1-0, 2-0, 1-1 тощо).
Підсумовування всіх рахунків, де City перемагає, дає вам їхню Ймовірність Перемоги.
Крок 4: Перетворення Ймовірності на Коефіцієнти
Це найбільш критичний крок у спортивній аналітиці. Ви повинні перевести свій відсоток у лінію ставок, щоб порівняти її з букмекером.
Формула:
Порівняння:
| Результат | Ймовірність Моделі | Ваші "Справжні" Коефіцієнти | Коефіцієнти Букмекера | Перевага (EV) | Дія |
|---|---|---|---|---|---|
| Перемога Man City | 65% | 1.54 | 1.45 | Негативна | Пропустити |
| Нічия | 20% | 5.00 | 4.50 | Негативна | Пропустити |
| Перемога Chelsea | 15% | 6.67 | 8.00 | Позитивна | СТАВКА |
У цьому сценарії, навіть якщо ваша модель вважає City ймовірним переможцем, цінність (value) на стороні Chelsea. Букмекер платить 8.00 (7/1) за результат, який, за вашою математикою, повинен бути 6.67. Протягом тисяч ставок прийняття цих цінних позицій гарантує прибуток.
Крок 5: Бектестування та Оптимізація
У вас є модель. Не робіть ставки на реальні гроші поки що. Ви повинні виконати Тестування на Невибіркових Даних (Out-of-Sample Testing).
Якщо ви створили свою модель, використовуючи дані сезонів 2020-2023, ви не можете тестувати її на тих самих сезонах. Ваша модель уже "знає" ці результати. Ви повинні протестувати її на сезоні 2024 (або наборі даних, який вона ще не бачила), щоб перевірити, чи дійсно вона прогнозує майбутнє.
Поширені Проблеми Моделювання:
- Перенавчання (Overfitting): Створення моделі, яка ідеально пояснює минуле, але зазнає невдачі в майбутньому, оскільки покладалася на шум/збіг, а не на сигнал.
- Упередженість "погляду вперед" (Look-ahead Bias): Випадкове включення даних у ваш тест, які не були б доступні на момент гри (наприклад, використання статистики за весь сезон для прогнозування гри 2-го тижня).
- Ігнорування Контексту: Модель не може читати Twitter. Вона не знає, що основний квотербек хворіє на грип. Ви повинні вручну коригувати значні зміни у складі.
Виконання: Розмір Ставок та Переваги Криптобукмекерів
Щойно ваша модель доведе, що має позитивний ROI (Return on Investment) протягом значного розміру вибірки (щонайменше 500 ставок), настав час виконувати.
Критерій Келлі (The Kelly Criterion)
Не робіть фіксованих ставок. Використовуйте стратегію розміру ставок, засновану на вашій перевазі. Критерій Келлі пропонує ставити відсоток вашого банкролу, пропорційний вашій перевазі.
- Спрощений Келлі: (Decimal Odds * Probability - 1) / (Decimal Odds - 1)
- Попередження: Повний Критерій Келлі є нестабільним. Більшість професіоналів роблять ставки "Чверть Келлі" або "Пів Келлі", щоб зменшити дисперсію.
Використання Криптобукмекерів
Кількісні ставки вимагають ефективності. Сайти криптоставок пропонують явні переваги для гравців, що базуються на моделях:
- Доступ до API: Багато сучасних криптобукмекерів дозволяють автоматизоване розміщення ставок через API, гарантуючи, що ви зловите лінію в ту секунду, коли ваша модель визначить цінність.
- Вищі Ліміти: На відміну від "м'яких" фіатних букмекерів, які швидко обмежують переможців, криптобіржі з високим обсягом та "шарпи" часто толерують виграшних гравців, оскільки вони допомагають формувати ефективність ринку.
- Миттєве Розрахування: При роботі з високооб'ємною моделлю грошовий потік – це головне. Миттєве виведення Bitcoin або USDT означає, що ви можете швидше обертати свій банкрол, щоденно збільшуючи свою перевагу, а не щотижня.
Практичні Поради для Вашої Першої Моделі
- Почніть з "Іграшкових" Моделей: Не намагайтеся негайно обіграти фінальну лінію NFL. Спробуйте моделювати щось менше, наприклад, очки 1-ї чверті або ставки на гравців (player props). Ці ринки менш ефективні.
- Відстежуйте "CLV": Closing Line Value (Цінність Фінального Коефіцієнта) є золотим стандартом моделювання. Якщо ви поставили на Chiefs за -3, а лінія закривається на -4.5, ваша модель працює, навіть якщо Chiefs програють гру. Постійне перевищення фінального коефіцієнта є найпевнішим показником довгострокової прибутковості.
- Вивчайте Python або R: Хоча Excel чудово підходить для навчання, згодом ви зіткнетеся з обмеженнями щодо обробки даних. Python (з бібліотеками, такими як Pandas та Scikit-learn) є галузевим стандартом для спортивної аналітики.
- Збирайте Власні Дані: Не покладайтеся на середні показники, знайдені на вебсайтах. Створюйте скрипти для збору детальних даних (play-by-play). Чим більш деталізовані ваші дані, тим унікальнішою буде ваша перевага.
Резюме
Створення предиктивної моделі — це не схема швидкого збагачення. Це проєкт у галузі data science, який вимагає терпіння, статистичної грамотності та суворої дисципліни.
- Визначте свою мету: Оберіть конкретний вид спорту та ринок.
- Зберіть дані: Зосередьтеся на предиктивних показниках ефективності, а не на об'ємній статистиці.
- Створіть механізм: Використовуйте Регресію або розподіл Пуассона для обчислення ймовірностей.
- Порівняйте коефіцієнти: Перетворіть ймовірності на ціни та знайдіть розбіжності на ринку.
- Бектестуйте: Доведіть, що модель працює на неперевірених даних.
- Виконайте: Використовуйте криптобукмекери для найкращих коефіцієнтів та швидкої ліквідності.
Коли ви перестанете перейматися тим, яка команда виграє, і почнете піклуватися про різницю між передбачуваною ймовірністю та справжньою ймовірністю, ви офіційно перейшли з категорії азартного гравця до спортивного інвестора.