
สำหรับนักเดิมพันกีฬาโดยส่วนใหญ่ การวางเดิมพันคือการกระทำที่มาจากสัญชาตญาณ เป็นการตัดสินใจที่ขับเคลื่อนด้วยเรื่องราว ความคลั่งไคล้ทีม หรือ "ความรู้สึกจากสัญชาตญาณ" ที่ได้จากการดูเกมสองสามเกมล่าสุด แม้ว่าแนวทางนี้อาจนำมาซึ่งชัยชนะเป็นครั้งคราว แต่ในทางคณิตศาสตร์แล้วเป็นไปไม่ได้เลยที่จะเอาชนะ sportsbooks ในระยะยาวโดยใช้แค่สัญชาตญาณเพียงอย่างเดียว เพราะ House Edge หรือที่เรียกว่า "vig" นั้นถูกออกแบบมาเพื่อบดขยี้การตัดสินใจที่เป็นอัตวิสัยเมื่อเวลาผ่านไป
ในการเปลี่ยนจากการเป็นนักพนันเพื่อความเพลิดเพลินไปสู่การเป็นนักลงทุนมืออาชีพที่ทำกำไรได้ (profitable sharp) คุณต้องหยุดการคาดเดาและเริ่มการคำนวณ นั่นหมายถึงการเปลี่ยนจากการเดิมพันที่ ทีม มาเป็นการเดิมพันที่ ตัวเลข
คู่มือนี้จะแนะนำให้คุณรู้จักกับโลกของการสร้างแบบจำลองเชิงคาดการณ์ (predictive modeling) เราจะตัดเรื่องราวที่มาจากสื่อออกไป และมุ่งเน้นไปที่การสร้างกลไกเชิงปริมาณที่สามารถสร้างเส้นอัตราต่อรองของตัวเองได้ โดยการเปรียบเทียบ "อัตราต่อรองที่แท้จริง" ของโมเดลของคุณกับอัตราต่อรองที่เสนอโดย crypto sportsbooks คุณสามารถระบุค่า Expected Value (+EV) ที่เป็นบวก และสร้างความได้เปรียบทางคณิตศาสตร์ได้

ปรัชญาของโมเดล: ราคาเทียบกับผลลัพธ์ (Price vs. Outcome)
ก่อนที่คุณจะเปิด Excel หรือเขียนโค้ด Python บรรทัดแรก คุณจะต้องเปลี่ยนความคิดของคุณเกี่ยวกับวัตถุประสงค์ของการเดิมพันเสียก่อน
ความผิดพลาดทั่วไปของมือใหม่คือการถามว่า "ใครจะชนะเกมนี้?" โมเดลคาดการณ์ไม่ได้ตอบคำถามนั้นโดยตรง แต่จะตอบแทนว่า: "ความเป็นไปได้ที่ทีมนี้จะชนะคือเท่าไหร่?"
หากโมเดลของคุณระบุว่า Kansas City Chiefs มีโอกาสชนะ 60% แต่อัตราต่อรองของ sportsbook บ่งชี้ว่ามีโอกาสชนะ 70% คุณไม่ควรเดิมพัน Chiefs แม้ว่าคุณจะคิดว่าพวกเขาจะชนะก็ตาม ในทางกลับกัน หาก sportsbook บ่งชี้โอกาสเพียง 40% Chiefs ก็จะกลายเป็นการเดิมพันที่มีมูลค่ามหาศาล (massive value bet)
เหตุผลที่การเดิมพันที่ขับเคลื่อนด้วยข้อมูลใช้งานได้ผล
Sportsbooks มีประสิทธิภาพ แต่มันก็ไม่สมบูรณ์แบบ พวกเขาต้องปรับสมดุลของบัญชีเพื่อลดความเสี่ยง ซึ่งมักจะปรับอัตราต่อรองโดยอิงจาก การรับรู้ของสาธารณชน (public perception) โมเดลที่แข็งแกร่งจะใช้ประโยชน์จากความไร้ประสิทธิภาพเหล่านี้
- ความเป็นกลาง (Objectivity): โมเดลจะละเลยกระแส มันไม่สนใจว่าผู้เล่นดาวเด่น "ถึงเวลา" ที่จะต้องทำผลงานได้ดี เว้นแต่ข้อมูลจะสนับสนุน
- ความสามารถในการปรับขนาด (Scalability): มนุษย์สามารถวิเคราะห์เกมสามเกมได้อย่างลึกซึ้งในหนึ่งชั่วโมง แต่โมเดลสามารถวิเคราะห์ได้ 300 เกมในสามวินาที
- วินัย (Discipline): โมเดลมอบกรอบการทำงานที่เข้มงวดสำหรับการวางเดิมพัน ป้องกันอารมณ์ที่พลุ่งพล่าน (emotional tilt) ซึ่งทำลายเงินทุน (bankrolls)
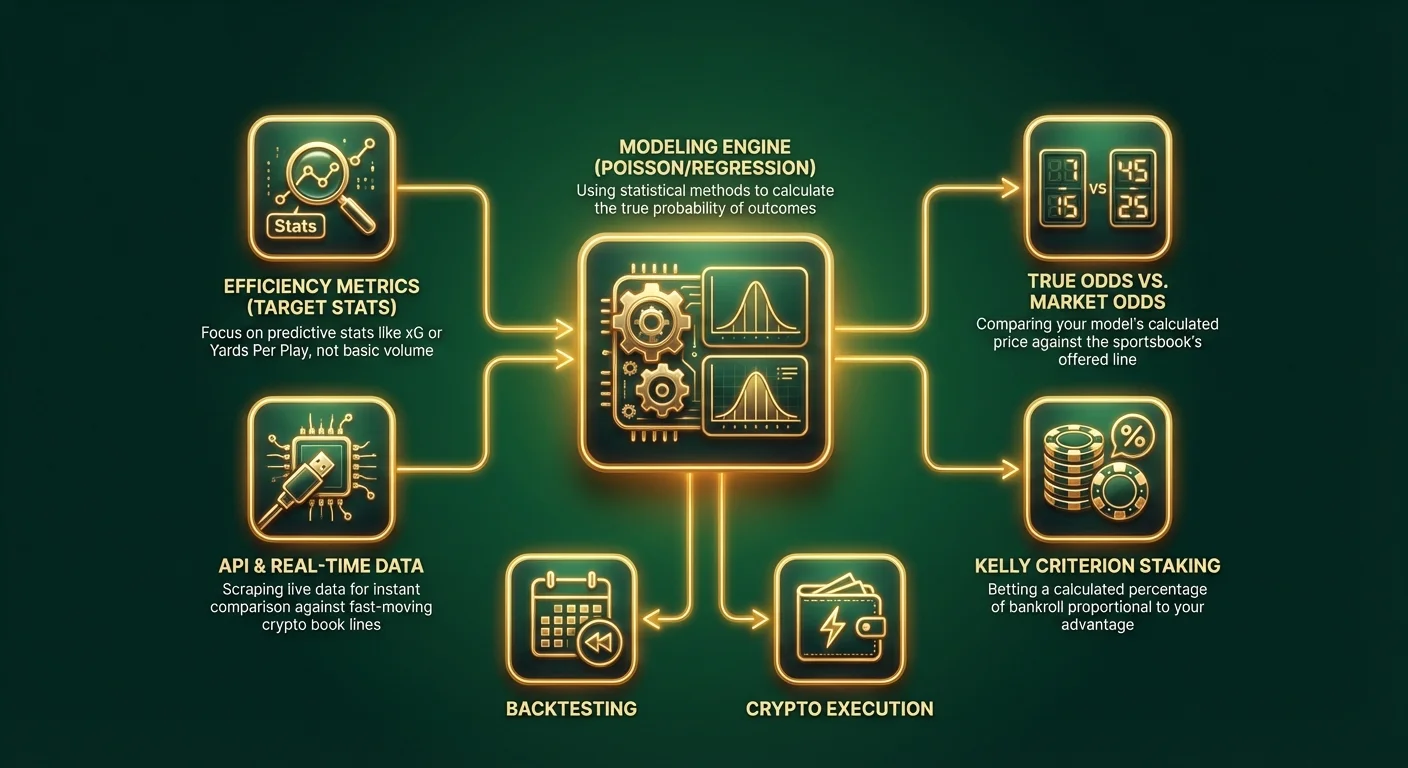
ขั้นตอนที่ 1: การกำหนดขอบเขตและการเลือกตัวแปร
อย่าพยายามสร้าง "Sports Betting Model" ที่ครอบคลุมทุกอย่าง ให้เริ่มต้นเล็กๆ เลือกกีฬาเดียวและตลาดที่เจาะจง
จุดเริ่มต้นที่แนะนำ:
- ผลรวมของแต้ม NBA (NBA Totals): เหตุการณ์การทำคะแนนมีปริมาณสูง ทำให้ความแปรปรวน (variance) ลดลงเมื่อเทียบกับกีฬาที่มีคะแนนต่ำ
- อัตราต่อรอง NFL (NFL Spreads): ตลาดที่มีสภาพคล่องสูง แม้ว่าจะค่อนข้างมีประสิทธิภาพมาก (ยากที่จะเอาชนะ)
- ฟุตบอล 1X2 (Moneyline): ยอดเยี่ยมสำหรับการสร้างแบบจำลองทางสถิติ เนื่องจากลักษณะการทำประตูเป็นแบบ Poisson distribution
Feature Engineering (การเลือกเมตริกของคุณ)
Garbage in, garbage out (ข้อมูลเข้าห่วย, ข้อมูลออกห่วย) คุณภาพของโมเดลของคุณขึ้นอยู่กับข้อมูลที่คุณป้อนเข้าไปทั้งหมด หลีกเลี่ยงสถิติพื้นฐาน เช่น "ชนะ/แพ้" หรือ "คะแนนต่อเกม (Points Per Game)" เนื่องจากสถิติเหล่านี้ได้ถูกนำไปรวมไว้ในอัตราต่อรองเกือบทั้งหมดแล้ว ให้มองหา เมตริกเชิงคาดการณ์ (predictive metrics) - สถิติที่มีความสัมพันธ์อย่างมากกับประสิทธิภาพในอนาคต
| กีฬา | สถิติพื้นฐาน (ควรหลีกเลี่ยง) | สถิติขั้นสูง (เป้าหมาย) | เหตุผลคือ? |
|---|---|---|---|
| NBA | Points Per Game | Offensive Efficiency (ORtg) / Pace | พิจารณาความเร็วของเกม ทีมที่เล่นเร็วจะทำคะแนนได้มากขึ้น แต่ไม่จำเป็นต้องดีกว่า |
| NFL | Total Yards | Yards Per Play / DVOA | สถิติปริมาณ (Volume stats) อาจทำให้เข้าใจผิด ประสิทธิภาพต่อการเล่น (efficiency per snap) คาดการณ์ความสำเร็จในอนาคตได้ดีกว่า |
| Soccer | Goals Scored | Expected Goals (xG) | xG วัดคุณภาพของโอกาสในการทำประตู ซึ่งคาดการณ์ได้ดีกว่าการทำเข้าประตูโดยโชคช่วย |
| MLB | Pitcher Wins | FIP (Fielding Independent Pitching) | แยกประสิทธิภาพของพิชเชอร์ออกจากกองหลังที่อยู่ข้างหลังเขา |
เคล็ดลับระดับมืออาชีพ: หากคุณเดิมพันด้วย Bitcoin หรือ stablecoins บน crypto sportsbooks สมัยใหม่ คุณมักจะสามารถเข้าถึงการผสานรวม API ได้ นักเดิมพันที่ชาญฉลาดใช้สคริปต์เพื่อดึงข้อมูลแบบเรียลไทม์ และเปรียบเทียบกับอัตราต่อรองบนแพลตฟอร์มคริปโตที่เคลื่อนไหวอย่างรวดเร็วได้ทันที
ขั้นตอนที่ 2: การเลือกวิธีการสร้างโมเดลของคุณ
มีวิธีการเบื้องต้นสามวิธีหลักสำหรับการสร้างโมเดลคาดการณ์
1. โมเดลจัดอันดับความแข็งแกร่ง (Power Ranking Model) (แบบง่าย)
วิธีนี้จะกำหนดคะแนนตัวเลขให้กับทุกทีม ส่วนต่างระหว่างคะแนนทั้งสองบวกกับการปรับสำหรับความได้เปรียบในการเล่นในบ้าน จะสร้างอัตราต่อรองขึ้นมา
- ตัวอย่าง: ทีม A (คะแนน 105) เทียบกับ ทีม B (คะแนน 98) ในสนามกลาง หมายความว่าทีม A เป็นทีมเต็ง 7 แต้ม
2. การวิเคราะห์ถดถอย (Regression Analysis) (ระดับกลาง)
วิธีนี้ใช้ข้อมูลในอดีตเพื่อค้นหาความสัมพันธ์ระหว่างตัวแปรกับผลลัพธ์ คุณอาจใช้การถดถอยเชิงเส้น (linear regression) เพื่อดูว่า "Passing Yards per Attempt" และ "Turnover Differential" สัมพันธ์กับส่วนต่างของคะแนนสุดท้ายอย่างไร
- เครื่องมือ: Microsoft Excel (Data Analysis Toolpak) หรือ Google Sheets
3. การแจกแจงปัวซอง (Poisson Distribution) (ขั้นสูง)
เหมาะสำหรับกีฬาที่มีคะแนนต่ำ เช่น ฟุตบอล (Soccer) หรือฮอกกี้ วิธีนี้จะคำนวณความน่าจะเป็นของเหตุการณ์อิสระจำนวนหนึ่ง (ประตู) ที่เกิดขึ้นภายในเวลาที่กำหนด
- แนวคิด: หากทีมทำประตูเฉลี่ย 1.5 ประตูต่อเกม คณิตศาสตร์ปัวซองสามารถบอกคุณได้ว่าพวกเขามีโอกาสทำประตู 0, 1, 2, หรือ 3 ประตูในแมตช์ถัดไปได้มากน้อยเพียงใด
ขั้นตอนที่ 3: การสร้างโมเดลปัวซองอย่างง่ายสำหรับฟุตบอล
เรามาดูตัวอย่างเชิงปฏิบัติของการสร้างโมเดลเพื่อคาดการณ์การแข่งขัน Premier League โดยใช้ Poisson Distribution ซึ่งทั้งหมดนี้สามารถทำได้ในสเปรดชีต
Phase A: การคำนวณความแข็งแกร่งในการรุกและการตั้งรับ
คุณต้องกำหนดว่าทีมนั้นดีขึ้นหรือแย่ลงเมื่อเทียบกับค่าเฉลี่ยของลีกมากน้อยเพียงใด
- ค่าเฉลี่ยของลีก: คำนวณค่าเฉลี่ยประตูที่ทำได้ต่อเกมโดยทีมเหย้าและทีมเยือนทั่วทั้งลีก (เช่น ค่าเฉลี่ยทีมเหย้า = 1.5, ค่าเฉลี่ยทีมเยือน = 1.2)
- ความแข็งแกร่งในการรุกของทีม: นำประตูเฉลี่ยที่ทีมทำได้มาหารด้วยค่าเฉลี่ยของลีก
- ความแข็งแกร่งในการตั้งรับของทีม: นำประตูเฉลี่ยที่ทีมเสียมาหารด้วยค่าเฉลี่ยของลีก
Phase B: การคาดการณ์จำนวนประตูที่คาดหวัง (Expected Goals - xG)
หากต้องการทราบว่าทีม A (เหย้า) มีแนวโน้มที่จะทำประตูได้กี่ประตูเมื่อเจอกับทีม B (เยือน) ให้ใช้สูตรนี้:
- ตัวอย่าง:
- ความแข็งแกร่งในการรุกของ Manchester City: 1.8 (แข็งแกร่งมาก)
- ความแข็งแกร่งในการตั้งรับของ Chelsea: 0.9 (ดีกว่าค่าเฉลี่ย)
- ค่าเฉลี่ยประตูทีมเหย้าของลีก: 1.5
- ประตูที่คาดการณ์ของ City:
ทำซ้ำสำหรับทีมเยือนเพื่อรับจำนวนประตูที่คาดการณ์ไว้
Phase C: การแปลงเป็นความน่าจะเป็น
เมื่อคุณมีคะแนนที่คาดการณ์ไว้แล้ว (เช่น City 2.43 - Chelsea 0.85) คุณใช้ฟังก์ชัน Poisson (มีอยู่ใน Excel เป็น =POISSON.DIST) เพื่อคำนวณโอกาสเป็นเปอร์เซ็นต์ของผลคะแนนที่เฉพาะเจาะจงแต่ละแบบ (1-0, 2-0, 1-1, ฯลฯ)
การรวมผลคะแนนทั้งหมดที่ City ชนะจะทำให้คุณได้ Win Probability ของพวกเขา
ขั้นตอนที่ 4: การแปลงความน่าจะเป็นเป็นอัตราต่อรอง
นี่คือขั้นตอนที่สำคัญที่สุดในการทำ sports analytics คุณต้องแปลงเปอร์เซ็นต์ของคุณให้เป็นเส้นอัตราต่อรองเพื่อเปรียบเทียบกับ sportsbook
สูตร:
การเปรียบเทียบ:
| ผลลัพธ์ | ความน่าจะเป็นตามโมเดลของคุณ | อัตราต่อรอง "ที่แท้จริง" ของคุณ | อัตราต่อรองของ Sportsbook | ความได้เปรียบ (EV) | การดำเนินการ |
|---|---|---|---|---|---|
| Man City Win | 65% | 1.54 | 1.45 | ติดลบ (Negative) | ผ่าน (Pass) |
| Draw | 20% | 5.00 | 4.50 | ติดลบ (Negative) | ผ่าน (Pass) |
| Chelsea Win | 15% | 6.67 | 8.00 | เป็นบวก (Positive) | BET (เดิมพัน) |
ในสถานการณ์นี้ แม้ว่าโมเดลของคุณจะคิดว่า City มีแนวโน้มที่จะชนะ แต่ มูลค่า (value) อยู่ที่ Chelsea Sportsbook จ่าย 8.00 (7/1) สำหรับผลลัพธ์ที่คณิตศาสตร์ของคุณบอกว่าควรจะเป็น 6.67 ในการเดิมพันหลายพันครั้ง การเลือกตำแหน่งที่มีมูลค่าเหล่านี้รับประกันผลกำไร
ขั้นตอนที่ 5: การทดสอบย้อนหลังและการเพิ่มประสิทธิภาพ (Backtesting and Optimization)
คุณมีโมเดลแล้ว แต่อย่าเพิ่งเดิมพันด้วยเงินจริง คุณต้องทำการ Out-of-Sample Testing
หากคุณสร้างโมเดลโดยใช้ข้อมูลจากฤดูกาล 2020-2023 คุณไม่สามารถทดสอบกับฤดูกาลเดียวกันได้ โมเดลของคุณ "รู้" ผลลัพธ์เหล่านั้นอยู่แล้ว คุณต้องทดสอบกับฤดูกาล 2024 (หรือชุดข้อมูลที่โมเดลไม่เคยเห็น) เพื่อดูว่ามันสามารถทำนายอนาคตได้จริงหรือไม่
ข้อผิดพลาดทั่วไปในการสร้างโมเดล:
- Overfitting: การสร้างโมเดลที่อธิบายอดีตได้อย่างสมบูรณ์แบบ แต่ล้มเหลวในอนาคตเพราะอาศัย "สัญญาณรบกวน/ความบังเอิญ" แทนที่จะเป็น "สัญญาณ" ที่แท้จริง
- Look-ahead Bias: การเผลอใส่ข้อมูลในการทดสอบที่ยังไม่มีในขณะที่ทำการแข่งขัน (เช่น การใช้สถิติทั้งฤดูกาลเพื่อคาดการณ์เกมสัปดาห์ที่ 2)
- Ignoring Context: โมเดลไม่สามารถอ่าน Twitter ได้ มันไม่รู้ว่า Quarterback ตัวจริงเป็นไข้ คุณต้องปรับด้วยตนเองสำหรับการเปลี่ยนแปลงผู้เล่นตัวหลักครั้งใหญ่
การดำเนินการ: การวางเดิมพันและข้อได้เปรียบของ Crypto
เมื่อโมเดลของคุณได้รับการพิสูจน์แล้วว่ามี ROI (Return on Investment) ที่เป็นบวกในช่วงขนาดตัวอย่างที่มีนัยสำคัญ (อย่างน้อย 500 รายการเดิมพัน) ก็ถึงเวลาดำเนินการ
The Kelly Criterion
อย่าเดิมพันด้วยจำนวนคงที่ (flat bet) ให้ใช้กลยุทธ์การวางเดิมพันตามความได้เปรียบของคุณ Kelly Criterion แนะนำให้เดิมพันเป็นเปอร์เซ็นต์ของเงินทุนของคุณตามสัดส่วนของความได้เปรียบที่คุณมี
- Kelly แบบง่าย: (Decimal Odds * Probability - 1) / (Decimal Odds - 1)
- คำเตือน: Kelly เต็มรูปแบบมีความผันผวนสูง ผู้เชี่ยวชาญส่วนใหญ่เดิมพัน "Quarter Kelly" หรือ "Half Kelly" เพื่อลดความแปรปรวน
การใช้ประโยชน์จาก Crypto Sportsbooks
การเดิมพันเชิงปริมาณ (Quantitative betting) ต้องใช้ประสิทธิภาพ ไซต์เดิมพัน Crypto มีข้อได้เปรียบที่แตกต่างกันสำหรับนักเดิมพันที่ใช้โมเดล:
- การเข้าถึง API: Crypto Books สมัยใหม่หลายแห่งอนุญาตให้เดิมพันอัตโนมัติผ่าน API ทำให้มั่นใจได้ว่าคุณจะได้รับอัตราต่อรองทันทีที่โมเดลของคุณระบุมูลค่าได้
- ขีดจำกัดที่สูงกว่า: แตกต่างจาก soft fiat books ที่จำกัดผู้ชนะอย่างรวดเร็ว ตลาดแลกเปลี่ยนคริปโตที่มีปริมาณสูงมักจะอดทนต่อผู้เล่นที่ชนะ เนื่องจากพวกเขาช่วยปรับปรุงประสิทธิภาพของตลาด
- การชำระเงินทันที: เมื่อใช้โมเดลที่มีปริมาณการเดิมพันสูง กระแสเงินสดคือสิ่งสำคัญ การถอน Bitcoin หรือ USDT ทันทีหมายความว่าคุณสามารถหมุนเวียนเงินทุนของคุณได้เร็วขึ้น ทำให้ความได้เปรียบของคุณเพิ่มขึ้นทุกวันแทนที่จะเป็นรายสัปดาห์
เคล็ดลับเชิงปฏิบัติสำหรับโมเดลแรกของคุณ
- เริ่มต้นด้วย "โมเดลของเล่น" (Toy Models): อย่าพยายามเอาชนะอัตราต่อรองปิดของ NFL ทันที ลองสร้างโมเดลที่เล็กกว่า เช่น คะแนนควอเตอร์แรก หรือ prop ผู้เล่น ตลาดเหล่านี้มีประสิทธิภาพน้อยกว่า
- ติดตาม "CLV": Closing Line Value คือมาตรฐานทองคำของการสร้างโมเดล หากคุณเดิมพัน Chiefs ที่ -3 และอัตราต่อรองปิดที่ -4.5 โมเดลของคุณก็ทำงานได้ดี แม้ว่า Chiefs จะแพ้เกมก็ตาม การเอาชนะอัตราต่อรองปิดอย่างสม่ำเสมอเป็นตัวบ่งชี้ที่แน่นอนที่สุดของการทำกำไรในระยะยาว
- เรียนรู้ Python หรือ R: แม้ว่า Excel จะดีสำหรับการเรียนรู้ แต่ในที่สุดคุณก็จะเจอกำแพงเรื่องการประมวลผลข้อมูล Python (พร้อมไลบรารีเช่น Pandas และ Scikit-learn) เป็นมาตรฐานอุตสาหกรรมสำหรับการวิเคราะห์กีฬา
- ดึงข้อมูลด้วยตนเอง (Scrape Your Own Data): อย่าพึ่งพาค่าเฉลี่ยที่พบในเว็บไซต์ สร้าง scrapers เพื่อรับข้อมูลแบบ play-by-play ข้อมูลของคุณละเอียดมากขึ้นเท่าใด ความได้เปรียบที่ไม่เหมือนใครของคุณก็จะมากขึ้นเท่านั้น
สรุป
การสร้างโมเดลคาดการณ์ไม่ใช่แผนการรวยเร็ว เป็นโครงการวิทยาศาสตร์ข้อมูลที่ต้องใช้ความอดทน ความรู้ทางสถิติ และวินัยที่เข้มงวด
- กำหนดเป้าหมายของคุณ: เลือกกีฬาและตลาดที่เฉพาะเจาะจง
- รวบรวมข้อมูล: มุ่งเน้นไปที่เมตริกประสิทธิภาพเชิงคาดการณ์ ไม่ใช่สถิติปริมาณ
- สร้างกลไก: ใช้ Regression หรือ Poisson distribution เพื่อคำนวณความน่าจะเป็น
- เปรียบเทียบอัตราต่อรอง: แปลงความน่าจะเป็นเป็นราคาและค้นหาความแตกต่างในตลาด
- Backtest: พิสูจน์ว่าโมเดลใช้งานได้กับข้อมูลที่ไม่เคยเห็น
- ดำเนินการ: ใช้ crypto sportsbooks เพื่ออัตราต่อรองที่ดีที่สุดและสภาพคล่องที่รวดเร็ว
เมื่อคุณหยุดสนใจว่าทีมใดจะชนะ และเริ่มสนใจความแตกต่างระหว่างความน่าจะเป็นโดยนัยและความน่าจะเป็นที่แท้จริง คุณก็ได้เลื่อนขั้นอย่างเป็นทางการจากการเป็นนักพนันไปเป็นนักลงทุนด้านกีฬาแล้ว