
For de aller fleste som tipper på sport, er det å plassere et spill en intuitiv handling. Det er en beslutning drevet av narrativ, favorisering, eller en «magefølelse» hentet fra å ha sett de siste kampene. Selv om denne tilnærmingen av og til kan gi gevinster, er det matematisk umulig å slå sportsbooksene på lang sikt ved å bruke intuisjon alene. Bookmakernes fordel, eller «vig» (kommisjon), er designet for å tære ned subjektive beslutninger over tid.
For å gå fra en fritidsgambler til en lønnsom «sharp», må du slutte å gjette og begynne å regne. Dette betyr at du må slutte å satse på lag og begynne å satse på tall.
Denne guiden introduserer deg for prediktiv modellering. Vi vil skrelle bort avhengigheten av medianarrativer og fokusere på å bygge en kvantitativ motor som gir ut sine egne odds. Ved å sammenligne modellens «sanne odds» med oddsen tilbudt av krypto-sportsbooks, kan du identifisere positiv Forventet Verdi (+EV) og sikre deg et matematisk fortrinn.

Filosofien bak modellen: Pris vs. Utfall
Før du åpner Excel eller skriver en linje med Python-kode, må du endre tankegangen din angående formålet med tippingen.
En vanlig nybegynnerfeil er å spørre: "Hvem vinner kampen?" En prediktiv modell svarer ikke direkte på det spørsmålet. I stedet svarer den: "Hva er sannsynligheten for at dette laget vinner?"
Hvis modellen din fastslår at Kansas City Chiefs har 60% sjanse for å vinne, men bookmakerens odds tilsier 70% sjanse, satser du ikke på Chiefs, selv om du tror de vinner. Omvendt, hvis bookmakeren tilsier 40% sjanse, blir Chiefs et massivt verdibet.
Hvorfor datadrevet tipping fungerer
Sportsbooks er effektive, men de er ikke perfekte. De må balansere bøkene sine for å redusere risiko, og de justerer ofte linjene basert på offentlig oppfatning. En robust modell utnytter disse ineffektivitetene.
- Objektivitet: Modeller ignorerer hype. De bryr seg ikke om en stjernespiller er "due" for en stor kamp, med mindre dataene støtter det.
- Skalerbarhet: Et menneske kan analysere tre kamper grundig på en time. En modell kan analysere 300 kamper på tre sekunder.
- Disiplin: Modeller gir et rigid rammeverk for innsats, noe som forhindrer den emosjonelle tilten som ødelegger bankroller.
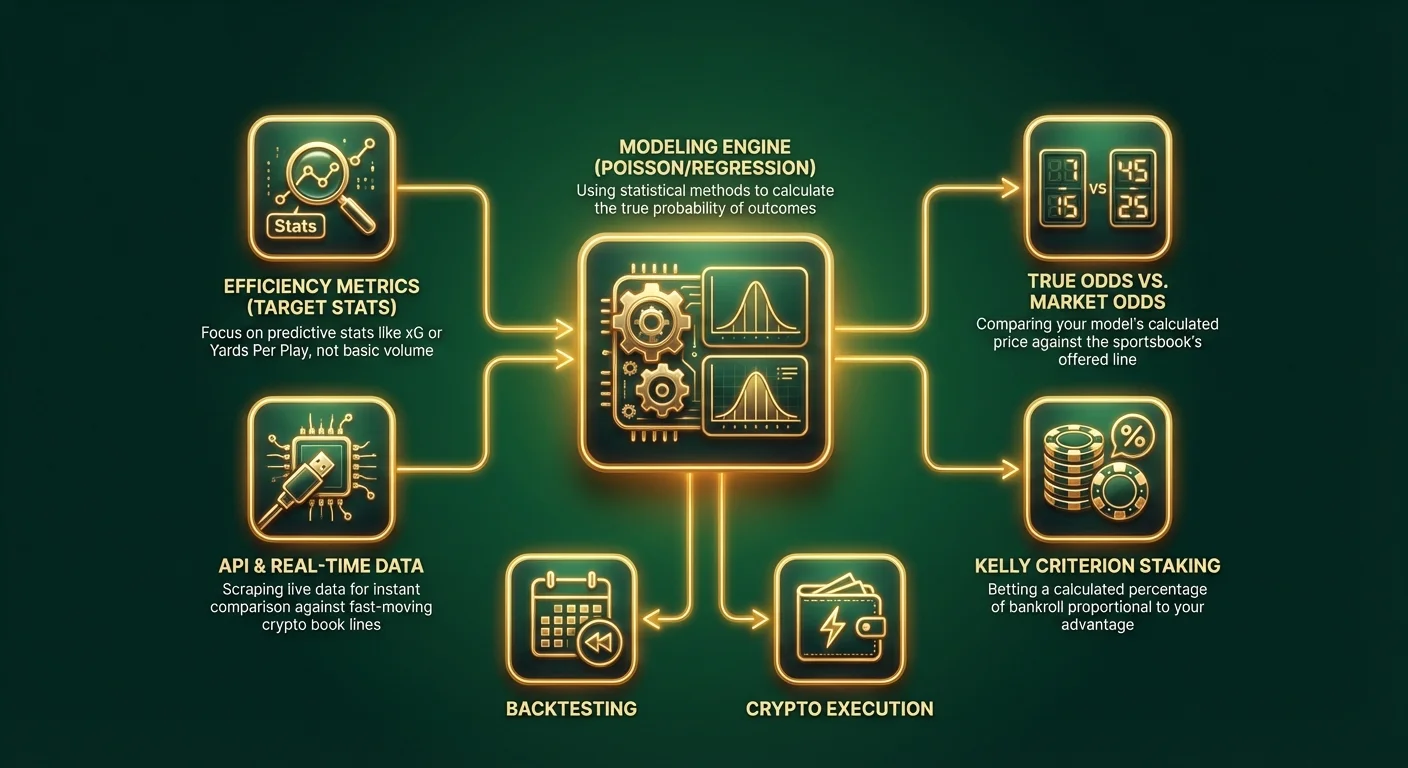
Steg 1: Definere omfang og variabelutvalg
Ikke prøv å bygge en «Sportsbettingmodell» som dekker alt. Start i det små. Velg én sport og ett spesifikt marked.
Anbefalte startpunkter:
- NBA Totals (Totalt antall poeng): Høyt volum av scoringshendelser reduserer variansen sammenlignet med idretter med lav poengsum.
- NFL Spreads (Handikap): Veldig likvide markeder, men svært effektive (vanskelig å slå).
- Fotball 1X2 (Moneyline): Utmerket for statistisk modellering på grunn av målinnets natur som følger Poisson-fordelingen.
Feature Engineering (Velge dine nøkkeltall)
Søppel inn, søppel ut. Kvaliteten på modellen din avhenger utelukkende av dataene du mater den med. Unngå grunnleggende statistikker som «Seire/Tap» eller «Poeng per kamp», da disse allerede er bakt inn i hver linje. Se etter prediktive målinger – statistikk som korrelerer sterkt med fremtidig ytelse.
| Sport | Grunnleggende statistikk (Unngå) | Avansert statistikk (Mål) | Hvorfor? |
|---|---|---|---|
| NBA | Points Per Game | Offensive Efficiency (ORtg) / Pace | Tar hensyn til tempoet i spillet; et raskt lag scorer mer, men er ikke nødvendigvis bedre. |
| NFL | Total Yards | Yards Per Play / DVOA | Volumstatistikk er misvisende; effektivitet per spill forutsier fremtidig suksess bedre. |
| Fotball | Goals Scored | Expected Goals (xG) | xG måler kvaliteten på sjansene som skapes, noe som er mer prediktivt enn heldige avslutninger. |
| MLB | Pitcher Wins | FIP (Fielding Independent Pitching) | Isolerer pitcherens ytelse fra forsvaret bak ham. |
Profftips: Hvis du satser med Bitcoin eller stablecoins på moderne krypto-sportsbooks, har du ofte tilgang til API-integrasjoner. Erfarne tippere bruker skript for å skrape sanntidsdata og sammenligne dem umiddelbart med oddsen på raske kryptoplattformer.
Steg 2: Velge din modelleringsmetode
Det er tre primære metoder på nybegynnernivå for å bygge en prediktiv modell.
1. Power Ranking-modellen (Enkel)
Denne tildeler en numerisk vurdering til hvert lag. Forskjellen mellom de to vurderingene, pluss en justering for hjemmebanefordel, skaper spreaden (handikapet).
- Eksempel: Lag A (Rating 105) mot Lag B (Rating 98) på nøytral bane tilsier at Lag A er en favoritt med 7 poeng.
2. Regresjonsanalyse (Middels)
Dette bruker historiske data for å finne korrelasjoner mellom variabler og utfall. Du kan kjøre en lineær regresjon for å se hvordan «Passing Yards per Attempt» og «Turnover Differential» korrelerer med den endelige poengmarginen.
- Verktøy: Microsoft Excel (Data Analysis Toolpak) eller Google Sheets.
3. Poisson-fordeling (Avansert)
Ideell for idretter med lav poengsum som fotball eller ishockey. Den beregner sannsynligheten for at et spesifikt antall uavhengige hendelser (mål) skjer innen en fastsatt tid.
- Konsept: Hvis et lag i gjennomsnitt scorer 1,5 mål per kamp, kan Poisson-matematikk fortelle deg nøyaktig hvor sannsynlig det er at de scorer 0, 1, 2 eller 3 mål i neste kamp.
Steg 3: Bygge en enkel Poisson-modell for fotball
La oss gå gjennom et praktisk eksempel på hvordan man bygger en modell for å forutsi en Premier League-kamp ved hjelp av Poisson-fordelingen. Dette kan gjøres utelukkende i et regneark.
Fase A: Beregn angreps- og forsvarsstyrke
Du må bestemme hvor mye bedre eller dårligere et lag er sammenlignet med ligagjennomsnittet.
- Ligagjennomsnitt: Beregn gjennomsnittlig antall mål scoret per kamp av et hjemmelag og et bortelag på tvers av hele ligaen. (f.eks. Hjemmegj.snitt = 1,5, Bortegj.snitt = 1,2).
- Lagets angrepsstyrke: Del lagets gjennomsnittlige antall mål scoret med ligagjennomsnittet.
- Lagets forsvarsstyrke: Del lagets gjennomsnittlige antall mål sluppet inn med ligagjennomsnittet.
Fase B: Prediker forventede mål (xG)
For å finne ut hvor mange mål Lag A (Hjemme) sannsynligvis vil score mot Lag B (Borte), bruk denne formelen:
- Eksempel:
- Manchester City Angrepsstyrke: 1,8 (Veldig sterk)
- Chelsea Forsvarsstyrke: 0,9 (Bedre enn gjennomsnittet)
- Liga Gj.snitt Hjemmemål: 1,5
- Predikerte City-mål:
Gjenta dette for bortelaget for å få deres predikerte målsum.
Fase C: Konverter til sannsynligheter
Nå som du har de predikerte resultatene (f.eks. City 2,43 – Chelsea 0,85), bruker du Poisson-funksjonen (tilgjengelig i Excel som =POISSON.DIST) for å beregne prosentandelen sjanse for hvert spesifikke resultat (1-0, 2-0, 1-1, osv.).
Å summere alle resultatene der City vinner, gir deg deres Vinner-sannsynlighet.
Steg 4: Konvertere sannsynlighet til odds
Dette er det mest kritiske trinnet innen sportsanalyse. Du må oversette prosentandelen din til en tippelinje for å sammenligne med sportsbooken.
Formelen:
Sammenligningen:
| Utfall | Modellens sannsynlighet | Dine "sanne" odds | Sportsbook-odds | Fordel (EV) | Handling |
|---|---|---|---|---|---|
| Man City Seier | 65% | 1,54 | 1,45 | Negativ | Pass |
| Uavgjort | 20% | 5,00 | 4,50 | Negativ | Pass |
| Chelsea Seier | 15% | 6,67 | 8,00 | Positiv | SPILL |
I dette scenarioet, selv om modellen din tror City er den sannsynlige vinneren, ligger verdien på Chelsea. Bookmakeren betaler 8.00 (7/1) på et utfall matematikken din sier burde vært 6.67. Over tusenvis av spill garanterer det å ta disse verdiposisjonene profitt.
Steg 5: Tilbakeføringstesting (Backtesting) og optimalisering
Du har en modell. Ikke sats ekte penger ennå. Du må utføre Out-of-Sample Testing (testing utenfor utvalget).
Hvis du bygget modellen din ved hjelp av data fra sesongene 2020–2023, kan du ikke teste den på de samme sesongene. Modellen din "vet" allerede de resultatene. Du må teste den på 2024-sesongen (eller et datasett den ikke har sett) for å se om den faktisk forutsier fremtiden.
Vanlige modelleringsfeller:
- Overfitting: Å skape en modell som perfekt forklarer fortiden, men som feiler i fremtiden fordi den stolte på støy/tilfeldigheter i stedet for signal.
- Look-ahead Bias (Fremoverskuende skjevhet): Å inkludere data i testen som ikke ville vært tilgjengelig på tidspunktet for kampen (f.eks. å bruke statistikk for hele sesongen for å forutsi en kamp i Uke 2).
- Ignorere kontekst: En modell kan ikke lese Twitter. Den vet ikke at start-Quarterbacken har influensa. Du må manuelt justere for store lagoppstillingsendringer.
Gjennomføring: Innsatsstrategi og Kryptofordeler
Når modellen din er bevist å ha en positiv ROI (Return on Investment) over et betydelig utvalg (minst 500 spill), er det på tide å utføre.
Kelly Criterion
Ikke sats flatt. Bruk en innsatsstrategi basert på fordelen din. Kelly Criterion foreslår å satse en prosentandel av bankrollen din proporsjonalt med fordelen din.
- Forenklet Kelly: (Desimal Odds * Sannsynlighet - 1) / (Desimal Odds - 1)
- Advarsel: Full Kelly er flyktig. De fleste proffer satser «Quarter Kelly» eller «Half Kelly» for å redusere varians.
Utnytte Krypto-Sportsbooks
Kvantitativ tipping krever effektivitet. Kryptotippesider tilbyr klare fordeler for modellbaserte tippere:
- API-tilgang: Mange moderne kryptobøker tillater automatisert tipping via API, noe som sikrer at du fanger oddsen i det sekundet modellen din identifiserer verdi.
- Høyere grenser: I motsetning til myke fiat-bøker som raskt begrenser vinnere, tolererer kryptobørser og "sharps" med høyt volum ofte vinnende spillere fordi de bidrar til å forme markedseffektiviteten.
- Umiddelbar utbetaling: Når man kjører en modell med høyt volum, er kontantstrøm avgjørende. Øyeblikkelige Bitcoin- eller USDT-uttak betyr at du kan sykle bankrollen din raskere, og forsterke fordelen din daglig i stedet for ukentlig.
Praktiske tips for din første modell
- Start med «lekemodeller»: Ikke prøv å slå NFLs sluttodds umiddelbart. Prøv å modellere noe mindre, for eksempel 1. Quarter-poeng eller spillerprops. Disse markedene er mindre effektive.
- Følg med på «CLV»: Closing Line Value (CLV) er gullstandarden for modellering. Hvis du satser på Chiefs til -3 og oddsen stenger på -4,5, fungerer modellen din, selv om Chiefs taper kampen. Konsekvent å slå sluttoddsen er den sikreste indikatoren på langsiktig lønnsomhet.
- Lær Python eller R: Selv om Excel er flott for læring, vil du etter hvert treffe en vegg med databehandling. Python (med biblioteker som Pandas og Scikit-learn) er industristandarden for sportsanalyse.
- Skrap dine egne data: Ikke stol på gjennomsnitt funnet på nettsteder. Bygg skrapere for å få «play-by-play»-data. Jo mer granulære dataene dine er, jo mer unik er fordelen din.
Oppsummering
Å bygge en prediktiv modell er ikke en snarvei til rikdom. Det er et datavitenskapsprosjekt som krever tålmodighet, statistisk kompetanse og streng disiplin.
- Definer målet ditt: Velg en spesifikk sport og et marked.
- Samle data: Fokuser på prediktive effektivitetsmålinger, ikke volumstatistikk.
- Bygg motoren: Bruk regresjon eller Poisson-fordeling for å beregne sannsynligheter.
- Sammenlign odds: Konverter sannsynligheter til priser og finn avvik i markedet.
- Tilbakeførstesting: Bevis at modellen fungerer på usette data.
- Gjennomfør: Bruk krypto-sportsbooks for best odds og rask likviditet.
Når du slutter å bry deg om hvilket lag som vinner og begynner å bry deg om forskjellen mellom implisitt sannsynlighet og sann sannsynlighet, har du offisielt uteksaminert deg fra en gambler til en sportsinvestor.