
대다수의 스포츠 베터에게 베팅은 직관적인 행위입니다. 이는 스토리, 팬심, 혹은 지난 몇 경기를 보고 얻은 "직감"에 의해 결정됩니다. 이러한 접근 방식이 가끔 승리를 가져다줄 수는 있지만, 직관만으로는 장기적으로 스포츠북을 이기는 것은 수학적으로 불가능합니다. 하우스 엣지, 즉 "비그(vig)"는 시간이 지남에 따라 주관적인 의사 결정을 깎아내리도록 설계되어 있습니다.
취미로 즐기는 도박꾼에서 수익을 내는 샤프(sharp, 전문 베터)로 전환하려면, 추측을 멈추고 계산을 시작해야 합니다. 이는 *팀*에 베팅하는 것에서 벗어나 *숫자*에 베팅하기 시작해야 함을 의미합니다.
이 가이드는 예측 모델링의 세계를 소개합니다. 우리는 미디어의 스토리텔링에 대한 의존을 제거하고, 자체적인 베팅 라인을 출력하는 정량적인 엔진을 구축하는 데 집중할 것입니다. 모델이 산출한 "진정한 확률(true odds)"을 암호화폐 스포츠북이 제공하는 배당률과 비교함으로써, 양의 기대값(+EV)을 식별하고 수학적 우위를 확보할 수 있습니다.

모델의 철학: 가격 대 결과
Excel을 열거나 Python 코드를 작성하기 전에, 베팅의 목적에 대한 사고방식을 전환해야 합니다.
초보자들이 흔히 저지르는 실수는 "누가 게임에서 이길 것인가?"라고 묻는 것입니다. 예측 모델은 그 질문에 직접 답하지 않습니다. 대신, 다음 질문에 답합니다. "이 팀이 이길 확률은 얼마인가?"
만약 당신의 모델이 Kansas City Chiefs가 60% 확률로 이길 것이라고 판단했는데, 스포츠북의 배당률이 70% 확률을 암시한다면, 당신이 Chiefs가 이길 것이라고 생각하더라도 베팅하지 않습니다. 반대로, 스포츠북이 40% 확률을 암시한다면, Chiefs는 엄청난 가치(value) 베팅이 됩니다.
데이터 기반 베팅이 효과적인 이유
스포츠북은 효율적이지만 완벽하지는 않습니다. 그들은 위험을 완화하기 위해 장부를 균형 있게 맞추어야 하며, 종종 대중의 인식에 기반하여 라인을 조정합니다. 강력한 모델은 이러한 비효율성을 활용합니다.
- 객관성: 모델은 과대광고를 무시합니다. 데이터가 뒷받침하지 않는 한, 스타 플레이어가 큰 경기를 할 "때가 됐다"는 사실에는 신경 쓰지 않습니다.
- 확장성: 인간은 한 시간에 세 경기를 깊이 분석할 수 있습니다. 모델은 3초 만에 300경기를 분석할 수 있습니다.
- 규율: 모델은 자금을 파괴하는 감정적인 틸트(tilt)를 방지하고 베팅 규모를 설정하는 엄격한 프레임워크를 제공합니다.
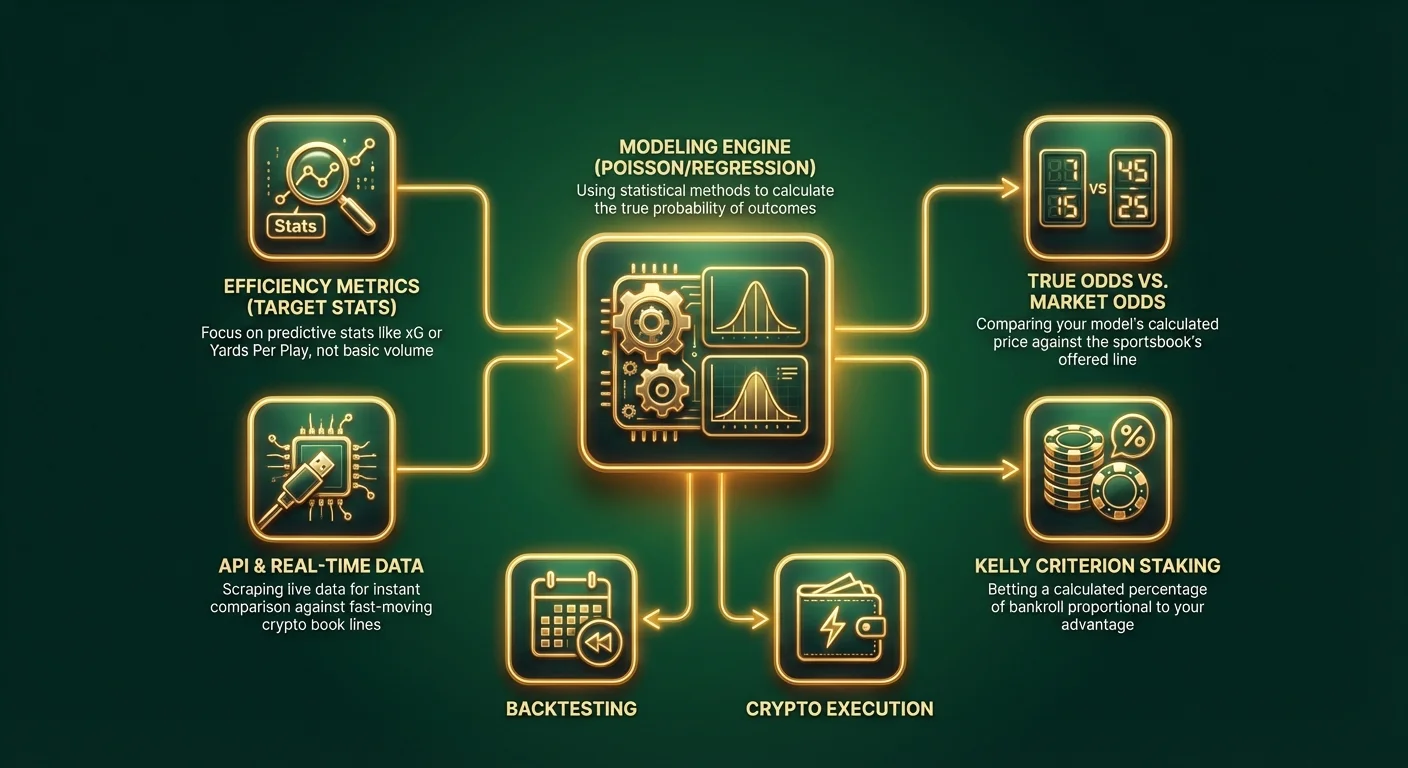
1단계: 범위 정의 및 변수 선택
모든 것을 포괄하는 "스포츠 베팅 모델"을 만들려고 하지 마십시오. 작게 시작하세요. 하나의 스포츠와 하나의 특정 마켓을 선택하십시오.
권장되는 시작점:
- NBA 토털(Totals): 득점 이벤트의 양이 많아 저득점 스포츠에 비해 분산(variance)이 적습니다.
- NFL 스프레드(Spreads): 유동성이 높은 시장이지만, 매우 효율적입니다(이기기 어려움).
- 축구 1X2 (승무패): 골 득점의 포아송 분포 특성으로 인해 통계적 모델링에 적합합니다.
특성 공학(Feature Engineering) (메트릭 선택)
쓰레기를 넣으면 쓰레기가 나옵니다(Garbage in, garbage out). 모델의 품질은 전적으로 입력하는 데이터에 달려 있습니다. "승/패" 또는 "경기당 득점"과 같은 기본 통계는 이미 모든 라인에 반영되어 있으므로 피하십시오. 미래의 성과와 강력하게 상관관계가 있는 예측 메트릭을 찾으십시오.
| 스포츠 | 기본 통계 (피해야 할 것) | 고급 통계 (목표) | 이유 |
|---|---|---|---|
| NBA | 경기당 득점 (Points Per Game) | 공격 효율성 (ORtg) / 페이스 (Pace) | 경기 속도를 설명합니다. 빠른 팀은 득점은 더 많이 하지만 반드시 더 나은 팀은 아닐 수 있습니다. |
| NFL | 총 야드 (Total Yards) | 플레이당 야드 (Yards Per Play) / DVOA | 양(volume) 통계는 오해의 소지가 있습니다. 스냅당 효율성이 미래 성공을 더 잘 예측합니다. |
| Soccer | 득점한 골 (Goals Scored) | 기대 득점 (xG, Expected Goals) | xG는 창출된 기회의 질을 측정하며, 이는 운 좋은 마무리보다 더 예측적입니다. |
| MLB | 투수 승리 (Pitcher Wins) | FIP (Fielding Independent Pitching) | 투수의 성능을 뒤에 있는 수비와 분리하여 측정합니다. |
전문가 팁: 최신 암호화폐 스포츠북에서 Bitcoin 또는 스테이블코인으로 베팅하는 경우, API 통합에 접근할 수 있는 경우가 많습니다. 노련한 베터들은 스크립트를 사용하여 실시간 데이터를 스크래핑하고, 빠르게 움직이는 암호화폐 플랫폼의 배당률과 즉시 비교합니다.
2단계: 모델링 방법 선택
예측 모델 구축을 위한 세 가지 주요 입문 단계 방법이 있습니다.
1. 파워 랭킹 모델 (단순)
이는 모든 팀에 숫자 등급을 할당합니다. 두 등급 간의 차이에 홈 구장 이점 조정을 더하여 스프레드를 생성합니다.
- 예시: 중립 구장에서의 팀 A (등급 105) 대 팀 B (등급 98)는 팀 A가 7점 차이의 강팀임을 의미합니다.
2. 회귀 분석 (중급)
이는 변수와 결과 간의 상관관계를 찾기 위해 과거 데이터를 사용합니다. 선형 회귀 분석을 실행하여 "시도당 패스 야드"와 "턴오버 마진"이 최종 점수 차이와 어떻게 상관관계가 있는지 확인할 수 있습니다.
- 도구: Microsoft Excel (데이터 분석 도구 모음) 또는 Google Sheets.
3. 포아송 분포 (고급)
축구나 하키와 같은 저득점 스포츠에 이상적입니다. 이는 정해진 시간 내에 특정 수의 독립적인 사건(골)이 발생할 확률을 계산합니다.
- 개념: 한 팀이 경기당 평균 1.5골을 기록한다면, 포아송 수학은 다음 경기에서 그 팀이 0골, 1골, 2골 또는 3골을 넣을 확률이 정확히 얼마인지 알려줄 수 있습니다.
3단계: 축구용 단순 포아송 모델 구축
포아송 분포를 사용하여 프리미어 리그 경기를 예측하는 모델을 구축하는 실질적인 예시를 살펴보겠습니다. 이는 전체 과정을 스프레드시트에서 수행할 수 있습니다.
단계 A: 공격 및 수비 강도 계산
팀이 리그 평균에 비해 얼마나 더 좋거나 나쁜지 결정해야 합니다.
- 리그 평균: 전체 리그에서 홈 팀과 원정 팀이 경기당 득점한 평균 골을 계산합니다. (예: 홈 평균 = 1.5, 원정 평균 = 1.2).
- 팀 공격 강도: 팀의 평균 득점 골을 리그 평균으로 나눕니다.
- 팀 수비 강도: 팀의 평균 실점 골을 리그 평균으로 나눕니다.
단계 B: 예상 득점 (xG) 예측
팀 A (홈)가 팀 B (원정)를 상대로 몇 골을 넣을 가능성이 높은지 알아보려면 다음 공식을 사용합니다.
- 예시:
- Manchester City 공격 강도: 1.8 (매우 강함)
- Chelsea 수비 강도: 0.9 (평균 이상)
- 리그 평균 홈 득점: 1.5
- 예상 City 득점:
원정 팀에 대해서도 이를 반복하여 예상 득점 총계를 얻습니다.
단계 C: 확률로 변환
이제 예상 점수(예: City 2.43 - Chelsea 0.85)를 얻었으므로, 포아송 함수(Excel에서 =POISSON.DIST로 사용 가능)를 사용하여 모든 특정 점수(1-0, 2-0, 1-1 등)가 나올 백분율 확률을 계산합니다.
City가 승리하는 모든 점수를 합산하면 승리 확률이 나옵니다.
4단계: 확률을 배당률로 변환
이는 스포츠 분석(sports analytics)에서 가장 중요한 단계입니다. 스포츠북과 비교하기 위해 백분율을 베팅 라인으로 변환해야 합니다.
공식:
비교:
| 결과 | 모델 확률 | 모델의 "진정한" 배당률 | 스포츠북 배당률 | 우위 (EV) | 조치 |
|---|---|---|---|---|---|
| Man City 승리 | 65% | 1.54 | 1.45 | 음수 | 패스 |
| 무승부 | 20% | 5.00 | 4.50 | 음수 | 패스 |
| Chelsea 승리 | 15% | 6.67 | 8.00 | 양수 | 베팅 |
이 시나리오에서, 모델이 City가 이길 가능성이 높다고 생각하더라도 가치(value)는 Chelsea에 있습니다. 스포츠북은 당신의 수학이 6.67이어야 한다고 말하는 결과에 대해 8.00(7/1)을 지불하고 있습니다. 수천 번의 베팅을 통해 이러한 가치 포지션을 취하는 것은 수익을 보장합니다.
5단계: 백테스팅 및 최적화
모델을 만들었습니다. 아직 실제 돈을 걸지 마십시오. 표본 외 테스트(Out-of-Sample Testing)를 수행해야 합니다.
2020-2023 시즌 데이터를 사용하여 모델을 구축했다면, 동일한 시즌에 대해 테스트할 수 없습니다. 모델은 이미 해당 결과를 "알고" 있습니다. 실제로 미래를 예측하는지 확인하기 위해 2024 시즌(또는 모델이 보지 못한 데이터셋)에 대해 테스트해야 합니다.
흔한 모델링 함정:
- 과적합 (Overfitting): 과거를 완벽하게 설명하지만, 신호(signal)보다는 노이즈/우연에 의존하여 미래에는 실패하는 모델을 만드는 것입니다.
- 선행 정보 편향 (Look-ahead Bias): 게임 당시에는 사용할 수 없었을 데이터를 실수로 테스트에 포함하는 것 (예: 2주차 경기를 예측하기 위해 시즌 전체 통계를 사용하는 것).
- 상황 무시 (Ignoring Context): 모델은 Twitter를 읽을 수 없습니다. 선발 쿼터백이 독감에 걸렸다는 사실을 알지 못합니다. 주요 라인업 변경 사항은 수동으로 조정해야 합니다.
실행: 베팅 규모 설정 및 암호화폐의 이점
모델이 충분한 표본 크기(최소 500회 베팅)에서 양의 ROI(투자 수익률)를 가진 것으로 입증되면, 이제 실행할 차례입니다.
켈리 공식 (The Kelly Criterion)
정액 베팅을 하지 마십시오. 당신의 우위(edge)에 기반한 베팅 규모 설정 전략을 사용하십시오. 켈리 공식(Kelly Criterion)은 당신의 우위에 비례하여 자금의 일정 비율을 베팅할 것을 제안합니다.
- 단순화된 켈리 공식: (소수점 배당률 * 확률 - 1) / (소수점 배당률 - 1)
- 경고: 전체 켈리 공식은 변동성이 큽니다. 대부분의 전문 베터는 분산을 줄이기 위해 "4분의 1 켈리" 또는 "절반 켈리"를 베팅합니다.
암호화폐 스포츠북 활용
정량적 베팅은 효율성을 요구합니다. 암호화폐 베팅 사이트는 모델 기반 베터에게 뚜렷한 이점을 제공합니다.
- API 접근: 많은 최신 암호화폐 북은 API를 통한 자동화된 베팅을 허용하여, 모델이 가치를 식별하는 즉시 라인을 잡을 수 있도록 보장합니다.
- 더 높은 한도: 우승자를 빠르게 제한하는 유연한 명목 화폐 북과는 달리, 고유동성 암호화폐 거래소와 샤프(전문 베터)들은 시장 효율성을 형성하는 데 도움이 되기 때문에 우승하는 플레이어에게 더 관대합니다.
- 즉각적인 정산: 대용량 모델을 운영할 때 현금 흐름이 중요합니다. 즉각적인 Bitcoin 또는 USDT 출금은 자금을 매주가 아닌 매일 더 빠르게 순환시켜 우위를 복리화할 수 있음을 의미합니다.
첫 모델을 위한 실용적인 팁
- "토이" 모델로 시작하세요: 당장 NFL 마감 라인을 이기려고 하지 마십시오. 1쿼터 점수나 선수 프로퍼티(player props)와 같이 더 작은 것을 모델링해 보세요. 이러한 시장은 효율성이 낮습니다.
- "CLV" 추적: 마감 라인 가치(CLV, Closing Line Value)는 모델링의 황금 표준입니다. 당신이 Chiefs에 -3에 베팅했는데 라인이 -4.5로 마감된다면, Chiefs가 경기에서 지더라도 당신의 모델은 작동하고 있는 것입니다. 지속적으로 마감 라인을 이기는 것은 장기적인 수익성을 나타내는 가장 확실한 지표입니다.
- Python 또는 R 학습: Excel은 학습에 훌륭하지만, 결국 데이터 처리의 한계에 부딪힐 것입니다. Python(Pandas 및 Scikit-learn과 같은 라이브러리 포함)은 스포츠 분석의 산업 표준입니다.
- 자체 데이터 스크래핑: 웹사이트에서 찾은 평균에 의존하지 마십시오. 플레이별 데이터(play-by-play data)를 얻기 위해 스크래퍼를 구축하십시오. 데이터가 세분화될수록 당신의 우위는 더 독특해집니다.
요약
예측 모델을 구축하는 것은 일확천금을 노리는 방식이 아닙니다. 이는 인내, 통계적 이해, 그리고 엄격한 규율을 요구하는 데이터 과학 프로젝트입니다.
- 목표 정의: 특정 스포츠와 마켓을 선택하십시오.
- 데이터 수집: 양(volume) 통계가 아닌 예측 효율성 메트릭에 집중하십시오.
- 엔진 구축: 회귀 분석 또는 포아송 분포를 사용하여 확률을 계산하십시오.
- 배당률 비교: 확률을 가격으로 변환하고 시장의 불일치(discrepancies)를 찾으십시오.
- 백테스팅: 모델이 보지 못한 데이터에서 작동함을 입증하십시오.
- 실행: 최고의 배당률과 빠른 유동성을 위해 암호화폐 스포츠북을 사용하십시오.
어떤 팀이 이기는지에 대한 관심을 멈추고, 암시된 확률과 진정한 확률 사이의 차이에 관심을 갖기 시작할 때, 당신은 공식적으로 도박꾼에서 스포츠 투자자로 졸업한 것입니다.