
ほとんどのスポーツベッターにとって、賭けは直感的な行為です。それは、物語や応援しているチーム、あるいは直近数試合を見たことで得た「勘」に動かされた決定です。このアプローチで時々勝つことはできても、直感だけを使ってスポーツブックに長期的に打ち勝つことは数学的に不可能です。ハウスエッジ、または「ヴィグ (手数料)」は、主観的な意思決定を時間をかけて削り取るように設計されています。
娯楽的なギャンブラーから利益を生むプロ(シャープ)に移行するには、推測をやめ、計算を始める必要があります。これは、チームに賭けることから離れ、数字に賭け始めることを意味します。
このガイドでは、予測モデリングの世界を紹介します。メディアの物語に頼るのをやめ、独自のベッティングラインを出力する定量的なエンジン構築に焦点を当てます。モデルが算出した「真のオッズ」を、クリプトスポーツブックが提供するオッズと比較することで、ポジティブな期待値 (+EV)を特定し、数学的な優位性を確保できます。

モデルの哲学:価格 vs. 結果
Excelを開いたり、Pythonコードを書き始めたりする前に、ベッティングの目的について考え方を変える必要があります。
初心者が犯しがちな間違いは、「どちらのチームが勝つか?」と問うことです。予測モデルはその質問に直接答えません。代わりに、次の問いに答えます。「このチームが勝つ確率はどれくらいか?」
もしあなたのモデルがカンザスシティ・チーフスが勝つ確率を60%と判断したが、スポーツブックのオッズが70%の確率を示唆している場合、たとえあなたがチーフスが勝つと思っていても、賭けてはいけません。逆に、スポーツブックが40%の確率を示唆しているならば、チーフスは大きなバリューベットとなります。
データ駆動型ベッティングが機能する理由
スポーツブックは効率的ですが、完璧ではありません。リスクを軽減するためにブックを調整する必要があり、しばしば世間の認識に基づいてラインを変動させます。堅牢なモデルはこれらの非効率性を悪用します。
- 客観性: モデルは誇大宣伝を無視します。データが裏付けない限り、スター選手がビッグゲームで「活躍するはず」だということには関心がありません。
- スケーラビリティ: 人間は1時間に3試合を深く分析できます。モデルは3秒で300試合を分析できます。
- 規律: モデルは厳格なステイキング(賭け金設定)の枠組みを提供し、バンクロールを破綻させる感情的な傾きを防ぎます。
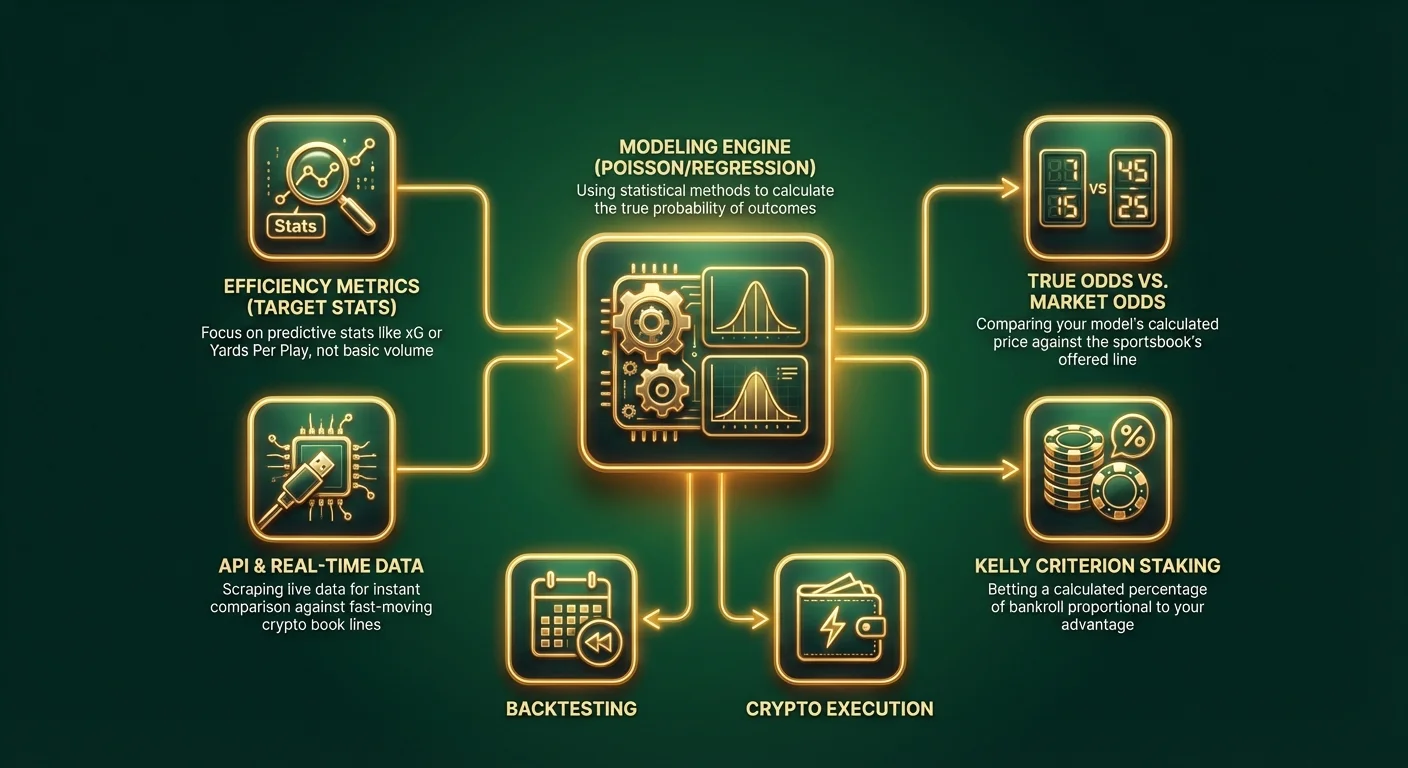
ステップ1:範囲の定義と変数の選択
すべてを網羅する「スポーツベッティングモデル」を構築しようとしないでください。小さく始めましょう。1つのスポーツと1つの特定のマーケットを選びます。
推奨される開始点:
- NBAトータル (Totals): スコアリングイベントの量が多いため、ロースコアのスポーツに比べて分散が少なくなります。
- NFLスプレッド (Spreads): 非常に流動性の高いマーケットですが、非常に効率的です(打ち破るのは難しい)。
- サッカー 1X2 (マネーライン): ゴールスコアリングの性質がポアソン分布に基づいているため、統計的モデリングに適しています。
特徴量エンジニアリング(メトリクスの選択)
ガベージ・イン、ガベージ・アウト(GIGO)。モデルの品質は、入力するデータに完全に依存します。「勝利/敗北」や「1試合あたりの平均得点」のような基本的なスタッツは避けてください。これらはすでにすべてのラインに織り込まれています。予測的なメトリクス、つまり将来のパフォーマンスと強く相関するスタッツを探してください。
| スポーツ | 基本的なスタッツ(回避) | 高度なスタッツ(目標) | 理由 |
|---|---|---|---|
| NBA | Points Per Game | Offensive Efficiency (ORtg) / Pace | ゲームの速度を考慮に入れています。速いチームは多く得点しますが、必ずしも優秀ではありません。 |
| NFL | Total Yards | Yards Per Play / DVOA | ボリュームスタッツは誤解を招きます。1スナップあたりの効率が将来の成功をより良く予測します。 |
| Soccer | Goals Scored | Expected Goals (xG) | xGは、創造されたチャンスの質を測定します。これは、幸運なフィニッシュよりも予測性が高いです。 |
| MLB | Pitcher Wins | FIP (Fielding Independent Pitching) | 投手自身のパフォーマンスを、その背後の守備から切り離して評価します。 |
プロのヒント: 最新のクリプトスポーツブックでBitcoinやステーブルコインで賭ける場合、API統合にアクセスできることがよくあります。熟練したベッターは、スクリプトを使用してリアルタイムのデータをスクレイピングし、動きの速いクリプトプラットフォームのオッズと瞬時に比較します。
ステップ2:モデリング方法の選択
予測モデルを構築するためのエントリーレベルの主要な方法は3つあります。
1. パワーランキングモデル(シンプル)
これは、すべてのチームに数値レーティングを割り当てます。2つのレーティングの差に、ホームフィールドアドバンテージの調整を加えることで、スプレッドを作成します。
- 例: チームA(レーティング105)vs チームB(レーティング98)が中立地で行われる場合、チームAは7点差のフェイバリットであることを示唆します。
2. 回帰分析(中級)
これは、変数と結果の間の相関関係を見つけるために、過去のデータを使用します。線形回帰を実行して、「試行あたりのパスヤード」や「ターンオーバー差」が最終的な点差とどのように相関するかを確認するかもしれません。
- ツール: Microsoft Excel(データ分析ツールパック)または Google Sheets。
3. ポアソン分布(上級)
サッカーやホッケーのようなロースコアのスポーツに最適です。固定された時間内に特定の数の独立したイベント(ゴール)が発生する確率を計算します。
- コンセプト: あるチームが1試合あたり平均1.5ゴールを記録する場合、ポアソン分布の計算により、次の試合で0、1、2、または3ゴールを決める可能性が正確にわかります。
ステップ3:サッカーのためのシンプルなポアソンモデルの構築
ポアソン分布を使用してプレミアリーグの試合を予測するモデルを構築する実用的な例を見てみましょう。これはすべてスプレッドシート内で実行できます。
フェーズA:攻撃力と守備力を計算する
リーグ平均と比較して、チームがどれだけ優れているか、または劣っているかを決定する必要があります。
- リーグ平均: リーグ全体のホームチームとアウェイチームが1試合あたりに記録した平均ゴール数を計算します(例: ホーム平均 = 1.5、アウェイ平均 = 1.2)。
- チーム攻撃力 (Team Attack Strength): チームの平均ゴール数をリーグ平均で割ります。
- チーム守備力 (Team Defense Strength): チームの平均失点数をリーグ平均で割ります。
フェーズB:予測ゴール数(xG)を予測する
チームA(ホーム)がチームB(アウェイ)に対してどれくらいのゴールを決めそうかを知るには、次の数式を使用します。
- 例:
- マンチェスター・シティの攻撃力: 1.8(非常に強い)
- チェルシーの守備力: 0.9(平均以上)
- リーグ平均ホームゴール: 1.5
- 予測されるシティのゴール数:
これをアウェイチームについても繰り返し、予測される総ゴール数を取得します。
フェーズC:確率への変換
予測されたスコア(例: シティ 2.43 - チェルシー 0.85)が得られたので、ポアソン関数(Excelでは =POISSON.DIST として利用可能)を使用して、すべての特定のスコアライン(1-0、2-0、1-1など)のパーセンテージでの確率を計算します。
シティが勝つすべてのスコアラインを合計すると、彼らの勝利確率 (Win Probability)が得られます。
ステップ4:確率をオッズに変換する
これはスポーツ分析において最も重要なステップです。パーセンテージをベッティングラインに変換し、スポーツブックと比較する必要があります。
数式:
比較:
| 結果 | モデルの確率 | あなたの「真の」オッズ | スポーツブックのオッズ | 優位性 (EV) | アクション |
|---|---|---|---|---|---|
| マンC勝利 | 65% | 1.54 | 1.45 | Negative | Pass |
| 引き分け | 20% | 5.00 | 4.50 | Negative | Pass |
| チェルシー勝利 | 15% | 6.67 | 8.00 | Positive | BET |
このシナリオでは、モデルがシティの勝利を予測していたとしても、バリュー(価値)はチェルシーにあります。スポーツブックは、数学的に6.67であるべき結果に対して8.00(7/1)を支払っています。数千回の賭けを通じて、これらのバリューポジションを取ることは利益を保証します。
ステップ5:バックテストと最適化
モデルができました。しかし、まだ実際のお金を賭けてはいけません。サンプル外テスト (Out-of-Sample Testing)を実行する必要があります。
2020年から2023年シーズンのデータを使用してモデルを構築した場合、同じシーズンでテストすることはできません。モデルはすでにそれらの結果を「知って」います。実際に将来を予測できるかどうかを確認するために、2024年シーズン(またはまだ見ていないデータセット)でテストする必要があります。
一般的なモデリングの落とし穴:
- 過剰適合 (Overfitting): 過去を完全に説明するが、シグナルではなくノイズや偶然に依存したために将来では失敗するモデルを作成すること。
- ルックアヘッド・バイアス (Look-ahead Bias): ゲーム時に利用できなかったはずのデータ(例: シーズン全体のスタッツをウィーク2の予測に使用する)を誤ってテストに含めてしまうこと。
- コンテキストの無視: モデルはTwitterを読むことができません。先発クォーターバックがインフルエンザにかかっていることを知りません。主要なラインナップの変更については手動で調整する必要があります。
実行:ステイキングとクリプトの利点
モデルが十分なサンプルサイズ(最低500ベット)でプラスのROI(投資収益率)を持つことが証明されたら、実行する時です。
ケリー基準 (The Kelly Criterion)
一律に賭ける(フラットベット)のはやめましょう。優位性に基づいてステイキング戦略を使用します。ケリー基準は、あなたの優位性に比例したバンクロールの割合を賭けることを推奨します。
- 簡易ケリー: (Decimal Odds * Probability - 1) / (Decimal Odds - 1)
- 警告: フルケリーは変動が激しいです。ほとんどのプロは分散を減らすために「クォーターケリー」または「ハーフケリー」で賭けます。
クリプトスポーツブックの活用
定量的なベッティングには効率が求められます。クリプトベッティングサイトは、モデルベースのベッターに明確な利点を提供します。
- APIアクセス: 多くの最新のクリプトブックではAPIを介した自動ベッティングが可能であり、モデルがバリューを特定した瞬間に確実にラインを捉えられます。
- より高いリミット: 勝者をすぐに制限するフィアット(法定通貨)のソフトブックとは異なり、高容量のクリプト交換所やシャープは、市場の効率性を高めるのに役立つため、勝ち続けているプレイヤーを許容することがよくあります。
- 即時決済: 高ボリュームのモデルを運用する場合、キャッシュフローが重要です。即時のBitcoinやUSDTの引き出しは、バンクロールをより速く循環させることができ、毎週ではなく毎日、優位性を複利で積み重ねることができます。
最初のモデルのための実践的なヒント
- 「おもちゃのモデル(Toy Models)」から始める: すぐにNFLの終値ラインを打ち破ろうとしないでください。第1クォーターのポイントやプレーヤープロップのような、より小さなものをモデリングしてみてください。これらのマーケットは非効率性が高いです。
- 「CLV」を追跡する: 終値ラインバリュー (Closing Line Value: CLV) は、モデリングのゴールドスタンダードです。チーフスに-3で賭けて、ラインが-4.5で終了した場合、チーフスが負けたとしてもあなたのモデルは機能しています。一貫して終値ラインを打ち破ることは、長期的な収益性の最も確実な指標です。
- PythonまたはRを学ぶ: Excelは学習には最適ですが、いずれデータ処理の壁にぶつかります。Python(PandasやScikit-learnのようなライブラリを使用)は、スポーツ分析の業界標準です。
- 独自のデータをスクレイピングする: ウェブサイトで見つけた平均値に頼らないでください。プレイごとのデータを入手するためのスクレイパーを構築します。データが詳細であるほど、あなたのエッジはユニークになります。
まとめ
予測モデルの構築は、一攫千金を狙うものではありません。それは忍耐、統計的リテラシー、そして厳格な規律を必要とするデータサイエンスプロジェクトです。
- 目標を定義する: 特定のスポーツとマーケットを選びます。
- データを収集する: ボリュームスタッツではなく、予測的な効率メトリクスに焦点を当てます。
- エンジンを構築する: 回帰分析またはポアソン分布を使用して確率を計算します。
- オッズを比較する: 確率を価格に変換し、市場の矛盾点を見つけます。
- バックテスト: 未知のデータでモデルが機能することを証明します。
- 実行する: 最高のオッズと迅速な流動性のためにクリプトスポーツブックを使用します。
どのチームが勝つかに関心を持つのをやめ、示唆された確率と真の確率の差に関心を持ち始めたとき、あなたは正式にギャンブラーからスポーツ投資家へと卒業したことになります。