
ज़्यादातर स्पोर्ट्स बेटर्स के लिए, दाँव लगाना सहज बोध (intuition) का कार्य होता है। यह नैरेटिव, फ़ैनडम, या पिछले कुछ गेम्स को देखकर विकसित हुई "गट फीलिंग" से प्रेरित निर्णय होता है। हालाँकि यह तरीका कभी-कभी जीत दिला सकता है, लेकिन केवल सहज बोध का उपयोग करके लंबे समय में स्पोर्ट्सबुक्स को हराना गणितीय रूप से असंभव है। हाउस एज, या "vig," को समय के साथ व्यक्तिपरक निर्णय लेने की क्षमता को खत्म करने के लिए डिज़ाइन किया गया है।
एक मनोरंजक जुआरी से एक लाभदायक शार्प (profitable sharp) बनने के लिए, आपको अंदाज़ा लगाना बंद करना होगा और गणना शुरू करनी होगी। इसका मतलब है टीमों पर बेट लगाने से दूर हटना और संख्याओं पर बेट लगाना शुरू करना।
यह गाइड प्रेडिक्टिव मॉडलिंग की दुनिया से परिचय कराती है। हम मीडिया नैरेटिव्स पर निर्भरता को खत्म करेंगे और एक ऐसा मात्रात्मक इंजन (quantitative engine) बनाने पर ध्यान केंद्रित करेंगे जो अपनी खुद की बेटिंग लाइन्स आउटपुट करता है। अपने मॉडल की "ट्रू ऑड्स" की तुलना क्रिप्टो स्पोर्ट्सबुक्स द्वारा दी गई ऑड्स से करके, आप सकारात्मक Expected Value (+EV) की पहचान कर सकते हैं और एक गणितीय बढ़त (mathematical edge) सुरक्षित कर सकते हैं।

मॉडल का दर्शन: कीमत बनाम परिणाम
Excel खोलने या Python कोड की एक लाइन लिखने से पहले, आपको बेटिंग के उद्देश्य के बारे में अपनी मानसिकता बदलनी होगी।
एक सामान्य नौसिखिया गलती यह पूछना है कि, "गेम कौन जीतेगा?" एक प्रेडिक्टिव मॉडल सीधे उस प्रश्न का उत्तर नहीं देता है। इसके बजाय, यह उत्तर देता है: "इस टीम के जीतने की क्या संभावना है?"
यदि आपका मॉडल यह निर्धारित करता है कि कैनसस सिटी चीफ़्स के जीतने की 60% संभावना है, लेकिन स्पोर्ट्सबुक की ऑड्स 70% संभावना दर्शाती हैं, तो आप चीफ़्स पर बेट नहीं लगाते हैं, भले ही आपको लगता हो कि वे जीतेंगे। इसके विपरीत, यदि स्पोर्ट्सबुक 40% संभावना दर्शाती है, तो चीफ़्स एक बहुत बड़ी वैल्यू बेट बन जाती है।
डेटा-आधारित बेटिंग क्यों काम करती है
स्पोर्ट्सबुक्स कुशल (efficient) हैं, लेकिन वे परफेक्ट नहीं हैं। उन्हें जोखिम कम करने के लिए अपने खाते को संतुलित करना होता है, अक्सर सार्वजनिक धारणा के आधार पर लाइन्स को शेड (shade) करना पड़ता है। एक मज़बूत मॉडल इन अक्षमताओं का फायदा उठाता है।
- वस्तुनिष्ठता (Objectivity): मॉडल प्रचार को अनदेखा करते हैं। उन्हें इस बात की परवाह नहीं है कि एक स्टार खिलाड़ी बड़े गेम के लिए "ड्यू" है या नहीं, जब तक कि डेटा इसका समर्थन नहीं करता।
- स्केलेबिलिटी (Scalability): एक इंसान एक घंटे में तीन गेम्स का गहराई से विश्लेषण कर सकता है। एक मॉडल तीन सेकंड में 300 गेम्स का विश्लेषण कर सकता है।
- अनुशासन (Discipline): मॉडल स्टेक लगाने के लिए एक कठोर ढाँचा प्रदान करते हैं, भावनात्मक टिल्ट (emotional tilt) को रोकते हैं जो बैंकरोल को नष्ट कर देता है।
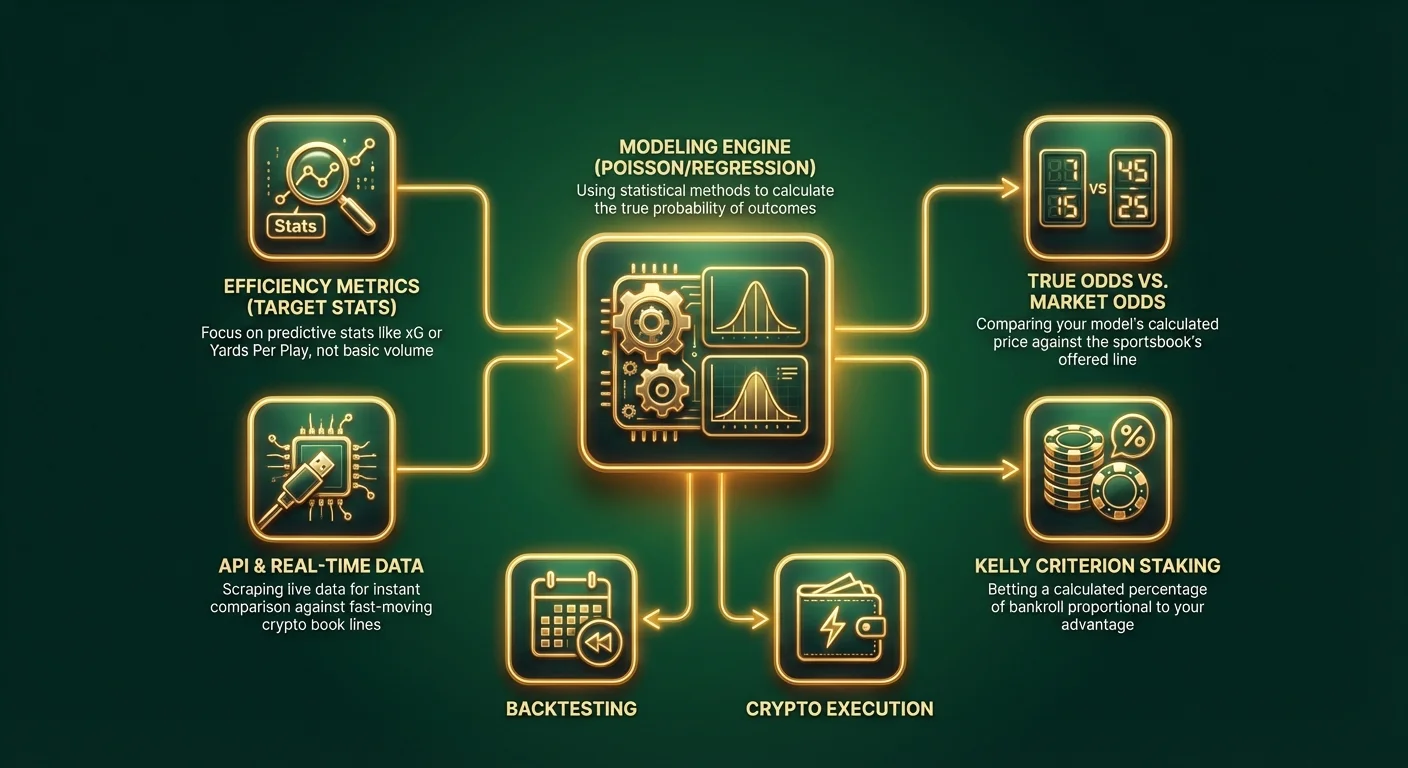
चरण 1: स्कोप को परिभाषित करना और वेरिएबल का चयन
एक "स्पोर्ट्स बेटिंग मॉडल" बनाने की कोशिश न करें जो सब कुछ कवर करे। छोटे से शुरू करें। एक खेल और एक विशिष्ट बाज़ार चुनें।
अनुशंसित प्रारंभिक बिंदु:
- NBA Totals: कम स्कोर वाले खेलों की तुलना में स्कोरिंग इवेंट्स की उच्च मात्रा भिन्नता (variance) को कम करती है।
- NFL Spreads: अत्यधिक लिक्विड बाज़ार, हालाँकि बहुत कुशल (हराना मुश्किल)।
- Soccer 1X2 (Moneyline): गोल स्कोरिंग की प्वासों डिस्ट्रीब्यूशन प्रकृति के कारण सांख्यिकीय मॉडलिंग के लिए बेहतरीन।
फीचर इंजीनियरिंग (अपने मेट्रिक्स का चयन करना)
गार्बेज इन, गार्बेज आउट (Garbage in, garbage out)। आपके मॉडल की गुणवत्ता पूरी तरह से उस डेटा पर निर्भर करती है जिसे आप इसे खिलाते हैं। "जीत/हार" या "प्रति गेम पॉइंट्स" जैसे बुनियादी आँकड़ों से बचें, क्योंकि ये पहले से ही हर लाइन में शामिल होते हैं। प्रेडिक्टिव मेट्रिक्स की तलाश करें - ऐसे आँकड़े जो भविष्य के प्रदर्शन के साथ मजबूती से सहसंबद्ध हों।
| खेल | बुनियादी आँकड़े (बचें) | उन्नत आँकड़े (लक्ष्य) | क्यों? |
|---|---|---|---|
| NBA | Points Per Game | Offensive Efficiency (ORtg) / Pace | गेम की गति के लिए खाते; एक तेज़ टीम अधिक स्कोर करती है लेकिन जरूरी नहीं कि बेहतर हो। |
| NFL | Total Yards | Yards Per Play / DVOA | वॉल्यूम आँकड़े भ्रामक होते हैं; प्रति स्नैप दक्षता भविष्य की सफलता का बेहतर अनुमान लगाती है। |
| Soccer | Goals Scored | Expected Goals (xG) | xG बनाए गए अवसरों की गुणवत्ता को मापता है, जो भाग्यशाली फिनिश की तुलना में अधिक प्रेडिक्टिव होता है। |
| MLB | Pitcher Wins | FIP (Fielding Independent Pitching) | गेंदबाज के प्रदर्शन को उसके पीछे की रक्षा से अलग करता है। |
प्रो टिप: यदि आप आधुनिक क्रिप्टो स्पोर्ट्सबुक्स पर Bitcoin या stablecoins के साथ बेटिंग कर रहे हैं, तो आपको अक्सर API इंटीग्रेशंस तक पहुँच मिलती है। समझदार बेटर्स रियल-टाइम डेटा स्क्रैप करने और तेजी से चलने वाले क्रिप्टो प्लेटफॉर्म पर ऑड्स के मुकाबले तुरंत इसकी तुलना करने के लिए स्क्रिप्ट का उपयोग करते हैं।
चरण 2: अपनी मॉडलिंग विधि चुनना
प्रेडिक्टिव मॉडल बनाने के लिए तीन प्राथमिक एंट्री-लेवल विधियाँ हैं।
1. द पावर रैंकिंग मॉडल (सरल)
यह हर टीम को एक संख्यात्मक रेटिंग प्रदान करता है। दो रेटिंग्स के बीच का अंतर, प्लस होम-फ़ील्ड एडवांटेज के लिए एक एडजस्टमेंट, स्प्रेड बनाता है।
- उदाहरण: टीम A (रेटिंग 105) बनाम टीम B (रेटिंग 98) एक न्यूट्रल फ़ील्ड पर टीम A को 7-पॉइंट का पसंदीदा दर्शाती है।
2. रिग्रेशन एनालिसिस (इंटरमीडिएट)
यह वैरिएबल्स और परिणामों के बीच सहसंबंध (correlations) खोजने के लिए ऐतिहासिक डेटा का उपयोग करता है। आप यह देखने के लिए एक लीनियर रिग्रेशन चला सकते हैं कि "Passing Yards per Attempt" और "Turnover Differential" अंतिम पॉइंट मार्जिन के साथ कैसे सहसंबंधित हैं।
- टूल: Microsoft Excel (Data Analysis Toolpak) या Google Sheets।
3. प्वासों डिस्ट्रीब्यूशन (Poisson Distribution) (एडवांस्ड)
फ़ुटबॉल या हॉकी जैसे कम स्कोर वाले खेलों के लिए आदर्श। यह एक निश्चित समय के भीतर होने वाली स्वतंत्र घटनाओं (गोल) की एक विशिष्ट संख्या की संभावना की गणना करता है।
- अवधारणा: यदि एक टीम प्रति गेम औसतन 1.5 गोल करती है, तो प्वासों मैथ आपको बता सकता है कि अगले मैच में उनके 0, 1, 2, या 3 गोल करने की कितनी संभावना है।
चरण 3: फ़ुटबॉल के लिए एक सरल प्वासों मॉडल बनाना
आइए प्वासों डिस्ट्रीब्यूशन का उपयोग करके एक प्रीमियर लीग मैच की भविष्यवाणी करने के लिए एक मॉडल बनाने के एक व्यावहारिक उदाहरण पर चलते हैं। यह पूरी तरह से एक स्प्रेडशीट में किया जा सकता है।
चरण A: आक्रमण और रक्षा शक्ति की गणना करें
आपको यह निर्धारित करने की आवश्यकता है कि एक टीम लीग के औसत की तुलना में कितनी बेहतर या बदतर है।
- लीग औसत: पूरे लीग में एक होम टीम और एक अवे टीम द्वारा प्रति गेम किए गए औसत गोल की गणना करें। (उदा., होम औसत = 1.5, अवे औसत = 1.2)।
- टीम आक्रमण शक्ति (Attack Strength): एक टीम द्वारा किए गए औसत गोल को लीग औसत से विभाजित करें।
- टीम रक्षा शक्ति (Defense Strength): एक टीम द्वारा दिए गए औसत गोल को लीग औसत से विभाजित करें।
चरण B: अपेक्षित गोल (Expected Goals - xG) की भविष्यवाणी करें
यह पता लगाने के लिए कि टीम A (होम) द्वारा टीम B (अवे) के खिलाफ कितने गोल किए जाने की संभावना है, इस फ़ॉर्मूले का उपयोग करें:
- उदाहरण:
- मैनचेस्टर सिटी आक्रमण शक्ति: 1.8 (बहुत मज़बूत)
- चेल्सी रक्षा शक्ति: 0.9 (औसत से बेहतर)
- लीग औसत होम गोल: 1.5
- भविष्यवाणी किए गए सिटी गोल:
अवे टीम के लिए उनके भविष्यवाणी किए गए कुल गोल प्राप्त करने के लिए इसे दोहराएँ।
चरण C: संभावनाओं में परिवर्तित करें
अब जब आपके पास भविष्यवाणी किए गए स्कोर (उदा., सिटी 2.43 - चेल्सी 0.85) हैं, तो आप प्वासों फ़ंक्शन का उपयोग करते हैं (Excel में =POISSON.DIST के रूप में उपलब्ध) हर विशिष्ट स्कोरलाइन (1-0, 2-0, 1-1, आदि) के प्रतिशत चांस की गणना करने के लिए।
उन सभी स्कोरलाइन्स को जोड़ना जहाँ सिटी जीतता है, आपको उनकी जीत की संभावना (Win Probability) देता है।
चरण 4: संभावना को ऑड्स में बदलना
यह स्पोर्ट्स एनालिटिक्स में सबसे महत्वपूर्ण कदम है। स्पोर्ट्सबुक के साथ तुलना करने के लिए आपको अपने प्रतिशत को एक बेटिंग लाइन में बदलना होगा।
फ़ॉर्मूला:
तुलना:
| परिणाम | आपके मॉडल की संभावना | आपकी "वास्तविक" ऑड्स | स्पोर्ट्सबुक ऑड्स | एज (EV) | कार्रवाई |
|---|---|---|---|---|---|
| Man City Win | 65% | 1.54 | 1.45 | नकारात्मक | Pass |
| Draw | 20% | 5.00 | 4.50 | नकारात्मक | Pass |
| Chelsea Win | 15% | 6.67 | 8.00 | सकारात्मक | BET |
इस परिदृश्य में, भले ही आपका मॉडल मानता हो कि सिटी के जीतने की संभावना है, वैल्यू चेल्सी पर है। स्पोर्ट्सबुक उस परिणाम पर 8.00 (7/1) का भुगतान कर रही है जिसे आपका गणित 6.67 होना कहता है। हज़ारों बेट्स पर, इन वैल्यू पोजीशन्स को लेने से मुनाफ़ा सुनिश्चित होता है।
चरण 5: बैकटेस्टिंग और ऑप्टिमाइज़ेशन
आपके पास एक मॉडल है। अभी असली पैसा बेट न करें। आपको आउट-ऑफ-सैंपल टेस्टिंग करनी होगी।
यदि आपने 2020-2023 सीज़न के डेटा का उपयोग करके अपना मॉडल बनाया है, तो आप उसी सीज़न पर इसका परीक्षण नहीं कर सकते हैं। आपका मॉडल पहले से ही उन परिणामों को "जानता है"। यह देखने के लिए कि क्या यह वास्तव में भविष्य की भविष्यवाणी करता है, आपको इसे 2024 सीज़न (या एक डेटासेट जिसे उसने नहीं देखा है) पर परीक्षण करना होगा।
सामान्य मॉडलिंग कमियाँ:
- ओवरफिटिंग: एक ऐसा मॉडल बनाना जो अतीत को पूरी तरह से समझाता है लेकिन भविष्य में विफल रहता है क्योंकि यह सिग्नल के बजाय नॉइज़/संयोग पर निर्भर था।
- लुक-अहेड बायस: गलती से आपके परीक्षण में ऐसा डेटा शामिल करना जो गेम के समय उपलब्ध नहीं होता (उदाहरण के लिए, वीक 2 गेम की भविष्यवाणी करने के लिए पूर्ण-सीज़न आँकड़ों का उपयोग करना)।
- संदर्भ को अनदेखा करना: एक मॉडल Twitter नहीं पढ़ सकता है। यह नहीं जानता कि शुरुआती क्वार्टरबैक को फ्लू है। आपको प्रमुख लाइनअप परिवर्तनों के लिए मैन्युअल रूप से एडजस्ट करना होगा।
निष्पादन: स्टेक लगाना और क्रिप्टो लाभ
एक बार जब आपका मॉडल एक महत्वपूर्ण सैंपल साइज़ (कम से कम 500 बेट्स) पर सकारात्मक ROI (Return on Investment) साबित कर देता है, तो इसे निष्पादित करने का समय आ जाता है।
केली क्राइटेरियन (The Kelly Criterion)
फ्लैट बेट न करें। अपनी बढ़त (edge) के आधार पर एक स्टेक लगाने की रणनीति का उपयोग करें। Kelly Criterion आपके बैंकरोल का एक प्रतिशत आपके लाभ के अनुपात में बेट लगाने का सुझाव देता है।
- सरलीकृत केली: (Decimal Odds * Probability - 1) / (Decimal Odds - 1)
- चेतावनी: पूर्ण केली अस्थिर (volatile) है। अधिकांश पेशेवर भिन्नता (variance) को कम करने के लिए "क्वार्टर केली" या "हाफ केली" बेट करते हैं।
क्रिप्टो स्पोर्ट्सबुक्स का लाभ उठाना
मात्रात्मक बेटिंग के लिए दक्षता की आवश्यकता होती है। क्रिप्टो बेटिंग साइटें मॉडल-आधारित बेटर्स के लिए विशिष्ट लाभ प्रदान करती हैं:
- API एक्सेस: कई आधुनिक क्रिप्टो बुक्स API के माध्यम से स्वचालित बेटिंग की अनुमति देते हैं, यह सुनिश्चित करते हुए कि जैसे ही आपका मॉडल वैल्यू पहचानता है, आप लाइन को पकड़ लेते हैं।
- उच्च सीमाएँ (Higher Limits): सॉफ्ट फिएट बुक्स के विपरीत जो जीतने वालों को जल्दी सीमित कर देते हैं, उच्च-वॉल्यूम क्रिप्टो एक्सचेंज और शार्प अक्सर जीतने वाले खिलाड़ियों को सहन करते हैं क्योंकि वे बाज़ार की दक्षता को आकार देने में मदद करते हैं।
- तत्काल निपटान (Instant Settlement): हाई-वॉल्यूम मॉडल चलाते समय, कैश फ़्लो किंग होता है। तत्काल Bitcoin या USDT निकासी का मतलब है कि आप साप्ताहिक के बजाय दैनिक आधार पर अपने बैंकरोल को तेज़ी से चक्रित कर सकते हैं, जिससे आपकी बढ़त बढ़ती है।
अपने पहले मॉडल के लिए व्यावहारिक सुझाव
- "टॉय" मॉडल से शुरू करें: तुरंत NFL क्लोजिंग लाइन को हराने की कोशिश न करें। कुछ छोटा मॉडल करने की कोशिश करें, जैसे 1st Quarter पॉइंट्स या प्लेयर प्रॉप्स। ये बाज़ार कम कुशल होते हैं।
- "CLV" को ट्रैक करें: क्लोजिंग लाइन वैल्यू (Closing Line Value) मॉडलिंग का गोल्ड स्टैंडर्ड है। यदि आप चीफ़्स पर -3 पर बेट लगाते हैं और लाइन -4.5 पर बंद होती है, तो आपका मॉडल काम कर रहा है, भले ही चीफ़्स गेम हार जाएं। लगातार क्लोजिंग लाइन को हराना लंबी अवधि की लाभप्रदता का सबसे निश्चित संकेतक है।
- Python या R सीखें: हालाँकि Excel सीखने के लिए शानदार है, लेकिन डेटा प्रोसेसिंग के साथ आप अंततः एक सीमा तक पहुँच जाएंगे। Python (Pandas और Scikit-learn जैसी लाइब्रेरी के साथ) स्पोर्ट्स एनालिटिक्स के लिए उद्योग मानक है।
- अपना खुद का डेटा स्क्रैप करें: वेबसाइटों पर पाए जाने वाले औसतों पर निर्भर न रहें। प्ले-बाय-प्ले डेटा प्राप्त करने के लिए स्क्रैपर बनाएं। आपका डेटा जितना अधिक दानेदार (granular) होगा, आपकी बढ़त उतनी ही अनूठी होगी।
सारांश
एक प्रेडिक्टिव मॉडल बनाना जल्दी अमीर बनने की योजना नहीं है। यह एक डेटा साइंस प्रोजेक्ट है जिसके लिए धैर्य, सांख्यिकीय साक्षरता और कठोर अनुशासन की आवश्यकता होती है।
- अपना लक्ष्य परिभाषित करें: एक विशिष्ट खेल और बाज़ार चुनें।
- डेटा इकट्ठा करें: वॉल्यूम आँकड़ों के बजाय प्रेडिक्टिव दक्षता मेट्रिक्स पर ध्यान केंद्रित करें।
- इंजन बनाएं: संभावनाओं की गणना के लिए रिग्रेशन या प्वासों डिस्ट्रीब्यूशन का उपयोग करें।
- ऑड्स की तुलना करें: संभावनाओं को कीमतों में बदलें और बाज़ार में विसंगतियों का पता लगाएं।
- बैकटेस्ट करें: साबित करें कि मॉडल अनदेखे डेटा पर काम करता है।
- निष्पादित करें: सर्वोत्तम ऑड्स और तेज़ लिक्विडिटी के लिए क्रिप्टो स्पोर्ट्सबुक्स का उपयोग करें।
जब आप इस बात की परवाह करना बंद कर देते हैं कि कौन सी टीम जीतती है और अंतर्निहित संभावना (implied probability) और वास्तविक संभावना के बीच के अंतर की परवाह करना शुरू कर देते हैं, तो आप आधिकारिक तौर पर एक जुआरी से एक स्पोर्ट्स इन्वेस्टर बन गए हैं।