
برای اکثریت قریب به اتفاق شرطبندان ورزشی، قرار دادن شرط عملی غریزی است. این تصمیمی است که تحت تأثیر روایتها، هواداری، یا یک "حس درونی" ناشی از تماشای چند بازی اخیر گرفته میشود. در حالی که این رویکرد میتواند گاهی اوقات منجر به برد شود، از نظر ریاضی غیرممکن است که بتوانید در بلندمدت، تنها با تکیه بر غریزه، بر سایتهای شرطبندی (sportsbooks) غلبه کنید. مزیت خانه، یا "vig"، به گونهای طراحی شده که تصمیمگیریهای ذهنی را به مرور زمان تحلیل ببرد.
برای گذار از یک قمارباز تفریحی به یک شرطبند حرفهای و سودآور، باید دست از حدس زدن بردارید و شروع به محاسبه کنید. این به معنای فاصله گرفتن از شرط بستن روی تیمها و شروع به شرط بستن روی اعداد است.
این راهنما شما را با دنیای مدلسازی پیشبینی آشنا میکند. ما اتکا به روایتهای رسانهای را کنار میگذاریم و بر ساختن یک موتور کمی تمرکز خواهیم کرد که خروجی آن خطوط شرطبندی مخصوص به خود مدل است. با مقایسه "احتمالات واقعی" مدل خود با ضریبهایی که توسط سایتهای شرطبندی کریپتویی ارائه میشود، میتوانید ارزش مورد انتظار مثبت (+EV) را شناسایی کرده و یک مزیت ریاضی را برای خود تضمین کنید.

فلسفه مدل: قیمت در برابر نتیجه
قبل از باز کردن Excel یا نوشتن یک خط کد Python، باید طرز فکر خود را در مورد هدف شرطبندی تغییر دهید.
یک اشتباه رایج در بین مبتدیان این است که میپرسند، "چه کسی بازی را میبرد؟" یک مدل پیشبینی مستقیماً به این سؤال پاسخ نمیدهد. در عوض، پاسخ میدهد: "احتمال برد این تیم چقدر است؟"
اگر مدل شما تعیین کند که تیم کنزاس سیتی چیفز (Kansas City Chiefs) ۶۰٪ شانس برد دارد، اما ضریبهای سایت شرطبندی نشاندهنده شانس ۷۰٪ باشد، شما روی چیفز شرط نمیبندید، حتی اگر فکر میکنید که آنها برنده خواهند شد. برعکس، اگر سایت شرطبندی شانس ۴۰٪ را نشان دهد، چیفز تبدیل به یک شرط با ارزش (value bet) بزرگ میشود.
چرا شرطبندی مبتنی بر داده کارساز است؟
سایتهای شرطبندی کارآمد هستند، اما کامل نیستند. آنها باید برای کاهش ریسک، دفتر خود را متعادل کنند و اغلب خطوط را بر اساس درک عمومی تنظیم میکنند. یک مدل قوی از این ناکارآمدیها بهره میبرد.
- عینیت (Objectivity): مدلها تبلیغات و بزرگنمایی را نادیده میگیرند. اگر دادهها پشتیبانی نکنند، برای آنها مهم نیست که یک بازیکن ستاره "باید" یک بازی بزرگ داشته باشد.
- قابلیت مقیاسپذیری (Scalability): یک انسان میتواند سه بازی را در یک ساعت به صورت عمقی تحلیل کند. یک مدل میتواند ۳۰۰ بازی را در سه ثانیه تحلیل کند.
- انضباط (Discipline): مدلها چارچوبی سختگیرانه برای تعیین میزان شرط (staking) فراهم میکنند و از نوسانات احساسی (emotional tilt) که سرمایه را از بین میبرند، جلوگیری میکنند.
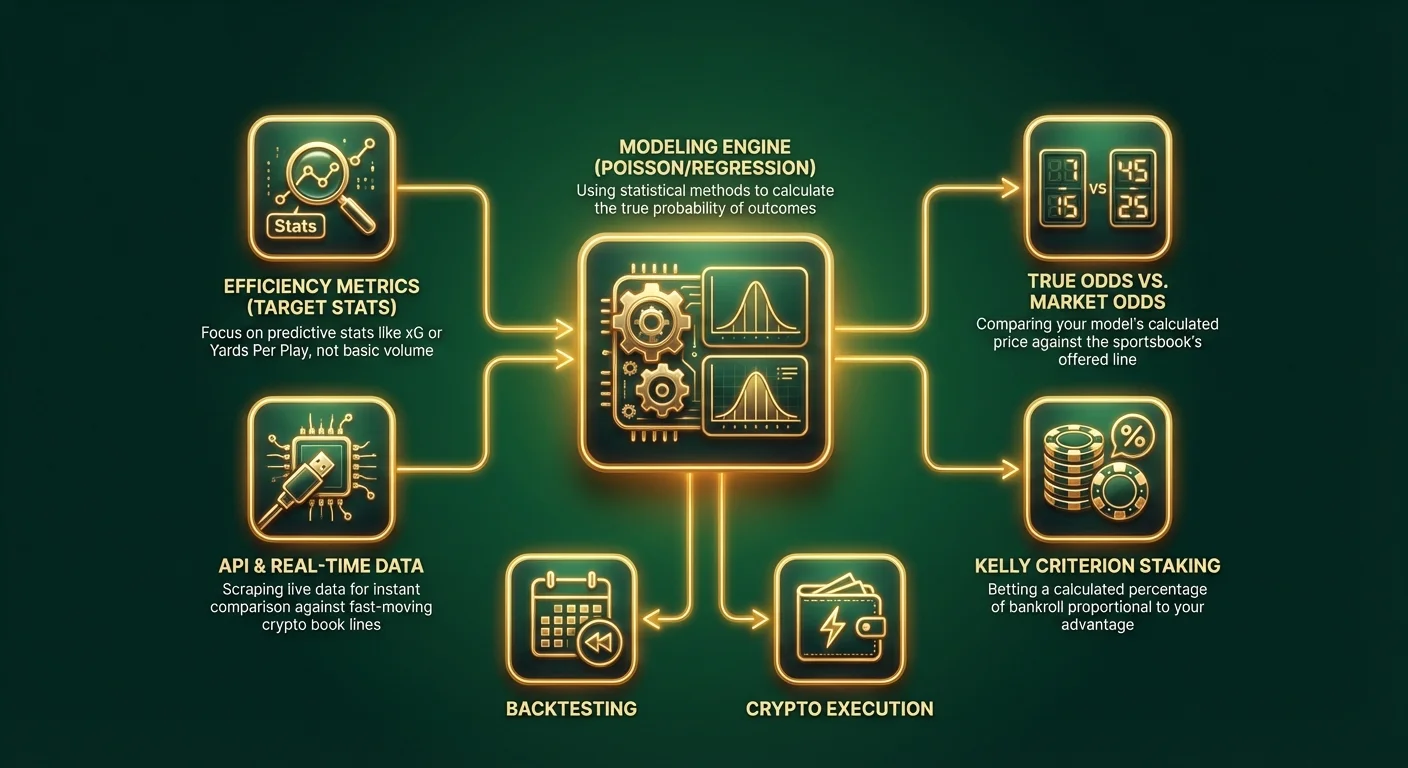
گام ۱: تعریف دامنه و انتخاب متغیر
سعی نکنید یک "مدل شرطبندی ورزشی" بسازید که همه چیز را پوشش دهد. کوچک شروع کنید. یک ورزش و یک بازار خاص را انتخاب کنید.
نقاط شروع توصیه شده:
- مجموع امتیازات NBA (NBA Totals): حجم بالای رویدادهای امتیازدهی، واریانس (variance) را در مقایسه با ورزشهای کمامتیاز کاهش میدهد.
- اختلاف امتیاز NFL (NFL Spreads): بازارهای بسیار نقدشونده، اگرچه بسیار کارآمد هستند (غلبه بر آنها دشوار است).
- 1X2 فوتبال (Moneyline): به دلیل ماهیت توزیع پواسون (Poisson distribution) در گلزنی، برای مدلسازی آماری عالی است.
مهندسی ویژگی (انتخاب معیارهای شما)
دادههای بیارزش ورودی، خروجی بیارزش. کیفیت مدل شما کاملاً به دادههایی که به آن میدهید، بستگی دارد. از آمارهای پایه مانند "برد/باخت" یا "امتیاز در هر بازی" اجتناب کنید، زیرا این موارد قبلاً در هر خط شرطبندی لحاظ شدهاند. به دنبال معیارهای پیشبینیکننده باشید – آمارهایی که همبستگی قوی با عملکرد آینده دارند.
| ورزش | آمار پایه (اجتناب کنید) | آمار پیشرفته (هدف) | چرا؟ |
|---|---|---|---|
| NBA | امتیاز در هر بازی | کارایی حمله (ORtg) / سرعت بازی (Pace) | سرعت بازی را در نظر میگیرد؛ تیم سریعتر امتیاز بیشتری میگیرد اما لزوماً بهتر نیست. |
| NFL | یاردهای کلی | یارد در هر حرکت (Yards Per Play) / DVOA | آمارهای حجمی گمراهکننده هستند؛ کارایی در هر اسنپ (snap) موفقیت آینده را بهتر پیشبینی میکند. |
| Soccer | گلهای زده شده | گلهای مورد انتظار (Expected Goals - xG) | xG کیفیت شانسهای ایجاد شده را اندازهگیری میکند که پیشبینیکنندهتر از ضربات شانسی است. |
| MLB | بردهای پیچر | FIP (Fielding Independent Pitching) | عملکرد پرتابکننده (pitcher) را از عملکرد دفاع پشت سر او جدا میکند. |
نکته حرفهای: اگر با Bitcoin یا stablecoins در سایتهای شرطبندی کریپتویی مدرن شرط میبندید، اغلب به یکپارچهسازیهای API دسترسی دارید. شرطبندان تیزبین از اسکریپتها برای استخراج دادههای همزمان (real-time) و مقایسه فوری آن با ضریبهای پلتفرمهای کریپتویی با حرکت سریع استفاده میکنند.
گام ۲: انتخاب روش مدلسازی شما
سه روش اولیه برای ساخت مدل پیشبینی وجود دارد.
۱. مدل رتبهبندی قدرت (ساده)
این مدل یک رتبهبندی عددی به هر تیم اختصاص میدهد. تفاوت بین این دو رتبهبندی، به علاوه یک تعدیل برای مزیت زمین خانه، اختلاف امتیاز (spread) را ایجاد میکند.
- مثال: تیم A (رتبه ۱۰۵) در مقابل تیم B (رتبه ۹۸) در زمین بیطرف به این معنی است که تیم A یک تیم موردعلاقه با ۷ امتیاز است.
۲. تحلیل رگرسیون (متوسط)
این روش از دادههای تاریخی برای یافتن همبستگی بین متغیرها و نتایج استفاده میکند. شما ممکن است یک رگرسیون خطی اجرا کنید تا ببینید چگونه "یاردهای پاس در هر تلاش" و "اختلاف در گردش توپ" با حاشیه امتیاز نهایی همبستگی دارند.
- ابزار: Microsoft Excel (Data Analysis Toolpak) یا Google Sheets.
۳. توزیع پواسون (پیشرفته)
این مدل برای ورزشهای کمامتیاز مانند فوتبال یا هاکی ایدهآل است. احتمال وقوع تعداد مشخصی از رویدادهای مستقل (گلها) را در یک زمان ثابت محاسبه میکند.
- مفهوم: اگر یک تیم به طور متوسط ۱.۵ گل در هر بازی به ثمر برساند، ریاضیات پواسون میتواند دقیقاً به شما بگوید که چقدر احتمال دارد که آنها ۰، ۱، ۲ یا ۳ گل در مسابقه بعدی به ثمر برسانند.
گام ۳: ساخت یک مدل ساده پواسون برای فوتبال
بیایید یک مثال عملی از ساخت مدلی برای پیشبینی یک مسابقه لیگ برتر با استفاده از توزیع پواسون را بررسی کنیم. این کار را میتوان به طور کامل در یک صفحه گسترده (spreadsheet) انجام داد.
فاز A: محاسبه قدرت حمله و دفاع
شما باید تعیین کنید که یک تیم در مقایسه با میانگین لیگ چقدر بهتر یا بدتر است.
- میانگین لیگ: میانگین گلهای زده شده در هر بازی توسط یک تیم میزبان و یک تیم میهمان را در کل لیگ محاسبه کنید. (مثلاً میانگین میزبان = ۱.۵، میانگین میهمان = ۱.۲).
- قدرت حمله تیم: میانگین گلهای زده شده تیم را بر میانگین لیگ تقسیم کنید.
- قدرت دفاع تیم: میانگین گلهای خورده تیم را بر میانگین لیگ تقسیم کنید.
فاز B: پیشبینی گلهای مورد انتظار (xG)
برای پیدا کردن اینکه تیم A (میزبان) احتمالاً چند گل در مقابل تیم B (میهمان) به ثمر میرساند، از این فرمول استفاده کنید:
- مثال:
- قدرت حمله منچستر سیتی: ۱.۸ (بسیار قوی)
- قدرت دفاع چلسی: ۰.۹ (بهتر از میانگین)
- میانگین گلهای خانگی لیگ: ۱.۵
- گلهای پیشبینی شده سیتی:
این کار را برای تیم میهمان تکرار کنید تا مجموع گلهای پیشبینی شده آنها را به دست آورید.
فاز C: تبدیل به احتمالات
اکنون که امتیازات پیشبینی شده را دارید (مثلاً سیتی ۲.۴۳ - چلسی ۰.۸۵)، از تابع پواسون (که در Excel به صورت =POISSON.DIST در دسترس است) برای محاسبه درصد شانس هر نتیجه مشخص (۱-۰، ۲-۰، ۱-۱ و غیره) استفاده میکنید.
جمع کردن تمام نتایجی که در آنها سیتی برنده میشود، احتمال برد آنها را به شما میدهد.
گام ۴: تبدیل احتمال به ضریب
این مهمترین گام در تحلیل ورزشی (sports analytics) است. برای مقایسه با سایت شرطبندی، باید درصد خود را به یک خط شرطبندی تبدیل کنید.
فرمول:
مقایسه:
| نتیجه | احتمال مدل شما | ضریب "واقعی" شما | ضریب سایت شرطبندی | مزیت (EV) | اقدام |
|---|---|---|---|---|---|
| برد منچستر سیتی | ۶۵٪ | ۱.۵۴ | ۱.۴۵ | منفی | رد کردن |
| تساوی | ۲۰٪ | ۵.۰۰ | ۴.۵۰ | منفی | رد کردن |
| برد چلسی | ۱۵٪ | ۶.۶۷ | ۸.۰۰ | مثبت | شرط ببندید |
در این سناریو، حتی اگر مدل شما فکر میکند سیتی برنده احتمالی است، ارزش روی چلسی است. سایت شرطبندی برای نتیجهای که محاسبات شما میگوید باید ۶.۶۷ باشد، ضریب ۸.۰۰ (۷/۱) پرداخت میکند. در طول هزاران شرط، گرفتن این موقعیتهای ارزشی، سود را تضمین میکند.
گام ۵: آزمون پسنگر (Backtesting) و بهینهسازی
شما یک مدل دارید. هنوز پول واقعی شرط نبندید. باید آزمون خارج از نمونه (Out-of-Sample Testing) را انجام دهید.
اگر مدل خود را با استفاده از دادههای فصلهای ۲۰۲۰ تا ۲۰۲۳ ساختید، نمیتوانید آن را روی همان فصلها آزمایش کنید. مدل شما قبلاً آن نتایج را "میداند". شما باید آن را روی فصل ۲۰۲۴ (یا مجموعه دادهای که ندیده است) آزمایش کنید تا ببینید آیا واقعاً آینده را پیشبینی میکند یا خیر.
اشتباهات رایج مدلسازی:
- بیشبرازش (Overfitting): ساخت مدلی که گذشته را کاملاً توضیح میدهد اما در آینده شکست میخورد، زیرا به جای سیگنال، بر نویز/تصادف تکیه کرده است.
- سوگیری پیشنگر (Look-ahead Bias): به اشتباه شامل کردن دادههایی در آزمون که در زمان بازی در دسترس نبودند (مثلاً استفاده از آمارهای کامل فصل برای پیشبینی بازی هفته دوم).
- نادیده گرفتن زمینه: یک مدل نمیتواند توییتر بخواند. نمیداند که کوارتربک اصلی آنفولانزا دارد. باید تغییرات مهم ترکیب را به صورت دستی تعدیل کنید.
اجرا: تعیین میزان شرط و مزایای کریپتو
زمانی که ثابت شد مدل شما دارای ROI (بازده سرمایهگذاری) مثبتی در یک نمونه قابل توجه (حداقل ۵۰۰ شرط) است، زمان اجرا فرا رسیده است.
معیار کلی (Kelly Criterion)
شرطهای ثابت (flat bet) نگذارید. از استراتژی تعیین میزان شرط بر اساس مزیت خود استفاده کنید. معیار کلی پیشنهاد میکند درصدی از سرمایه خود را متناسب با مزیت خود شرط ببندید.
- کلی ساده شده: (Decimal Odds * Probability - 1) / (Decimal Odds - 1)
- هشدار: معیار کامل کلی (Full Kelly) نوسانپذیر است. اکثر حرفهایها برای کاهش واریانس، "یک چهارم کلی" یا "نصف کلی" شرط میبندند.
استفاده از مزایای سایتهای شرطبندی کریپتویی
شرطبندی کمی به کارایی نیاز دارد. سایتهای شرطبندی کریپتویی مزایای مشخصی برای شرطبندان مبتنی بر مدل ارائه میدهند:
- دسترسی به API: بسیاری از سایتهای کریپتویی مدرن امکان شرطبندی خودکار از طریق API را میدهند و تضمین میکنند که به محض شناسایی ارزش توسط مدل شما، آن خط را شکار کنید.
- حدود بالاتر: برخلاف سایتهای فیات (fiat books) که برندگان را به سرعت محدود میکنند، صرافیهای پرحجم و حرفهایهای کریپتو اغلب بازیکنان برنده را تحمل میکنند زیرا آنها به شکلدهی کارایی بازار کمک میکنند.
- تسویه حساب فوری: هنگام اجرای یک مدل با حجم بالا، جریان نقدی اهمیت حیاتی دارد. برداشتهای فوری Bitcoin یا USDT به این معنی است که میتوانید سرمایه خود را سریعتر بچرخانید و مزیت خود را روزانه به جای هفتگی تقویت کنید.
نکات عملی برای اولین مدل شما
- با مدلهای "آزمایشی" شروع کنید: سعی نکنید بلافاصله خط بسته شدن NFL را شکست دهید. سعی کنید چیز کوچکتری مانند امتیازات کوارتر اول یا آمارهای بازیکنان را مدلسازی کنید. این بازارها کارایی کمتری دارند.
- ارزش خط بسته شدن (CLV) را دنبال کنید: Closing Line Value استاندارد طلایی مدلسازی است. اگر روی چیفز در ضریب -۳ شرط میبندید و خط در -۴.۵ بسته میشود، مدل شما کار میکند، حتی اگر چیفز بازی را ببازد. شکست دادن مداوم خط بسته شدن مطمئنترین شاخص سودآوری بلندمدت است.
- Python یا R را بیاموزید: در حالی که Excel برای یادگیری عالی است، در نهایت با پردازش دادهها به دیوار برخورد خواهید کرد. Python (با کتابخانههایی مانند Pandas و Scikit-learn) استاندارد صنعتی برای تحلیل ورزشی است.
- دادههای خود را استخراج کنید: به میانگینهای یافت شده در وبسایتها تکیه نکنید. اسکریپتهایی برای گرفتن دادههای جزء به جزء بازیها بسازید. هرچه دادههای شما جزئیتر باشد، مزیت شما منحصربهفردتر خواهد بود.
خلاصه
ساخت یک مدل پیشبینی یک طرح یک شبه پولدار شدن نیست. این یک پروژه علم داده است که نیازمند صبر، سواد آماری و انضباط سختگیرانه است.
- هدف خود را تعریف کنید: یک ورزش و بازار خاص را انتخاب کنید.
- جمعآوری داده: بر معیارهای کارایی پیشبینیکننده تمرکز کنید، نه آمارهای حجمی.
- ساخت موتور: از توزیع رگرسیون یا پواسون برای محاسبه احتمالات استفاده کنید.
- مقایسه ضریبها: احتمالات را به قیمت تبدیل کنید و مغایرتها را در بازار پیدا کنید.
- آزمون پسنگر (Backtest): ثابت کنید که مدل روی دادههای دیده نشده کار میکند.
- اجرا: از سایتهای شرطبندی کریپتویی برای بهترین ضریبها و نقدینگی سریع استفاده کنید.
وقتی دیگر برایتان مهم نباشد کدام تیم میبرد و اهمیت به تفاوت بین احتمال ضمنی و احتمال واقعی را شروع کنید، رسماً از یک قمارباز به یک سرمایهگذار ورزشی تبدیل شدهاید.