
For langt de fleste sportsbettere er et væddemål en handling drevet af intuition. Det er en beslutning baseret på historier, fandom eller en "mavefornemmelse" udledt af at se de seneste par kampe. Selvom denne tilgang lejlighedsvis kan give sejre, er det matematisk umuligt at slå bookmakerne på lang sigt udelukkende ved hjælp af intuition. Bookmakernes fordel, eller "vig," er designet til at nedbryde subjektiv beslutningstagning over tid.
For at skifte fra at være en fritidsspiller til en profitabel 'sharp', skal du stoppe med at gætte og begynde at regne. Det betyder, at du skal bevæge dig væk fra at vædde på hold og i stedet begynde at vædde på tal.
Denne guide introducerer dig til verdenen af prædiktiv modellering. Vi vil fjerne afhængigheden af mediernes historier og fokusere på at bygge en kvantitativ motor, der producerer sine egne betting-linjer. Ved at sammenligne din models "sande odds" med de odds, der tilbydes af krypto sportsbooks, kan du identificere positiv Expected Value (+EV) og sikre dig en matematisk fordel.

Modellens Filosofi: Pris versus Udfald
Før du åbner Excel eller skriver en linje Python-kode, skal du ændre din tankegang omkring målet med betting.
En almindelig nybegynderfejl er at spørge: "Hvem vinder kampen?" En prædiktiv model besvarer ikke det spørgsmål direkte. I stedet svarer den: "Hvad er sandsynligheden for, at dette hold vinder?"
Hvis din model bestemmer, at Kansas City Chiefs har 60% chance for at vinde, men bookmakerens odds antyder 70% chance, så vædder du ikke på Chiefs, selvom du tror, de vinder. Omvendt, hvis bookmakeren antyder 40% chance, bliver Chiefs et kæmpe value bet.
Derfor Virker Datadrevet Betting
Bookmakere er effektive, men de er ikke perfekte. De er nødt til at balancere deres bøger for at mindske risikoen og justerer ofte linjer baseret på den offentlige mening. En robust model udnytter disse ineffektiviteter.
- Objektivitet: Modeller ignorerer hype. De er ligeglade med, om en stjernespiller er "due" til en stor kamp, medmindre data understøtter det.
- Skalerbarhed: Et menneske kan analysere tre kampe dybt på en time. En model kan analysere 300 kampe på tre sekunder.
- Disciplin: Modeller giver en stiv ramme for staking, hvilket forhindrer den følelsesmæssige 'tilt', der ødelægger bankrolls.
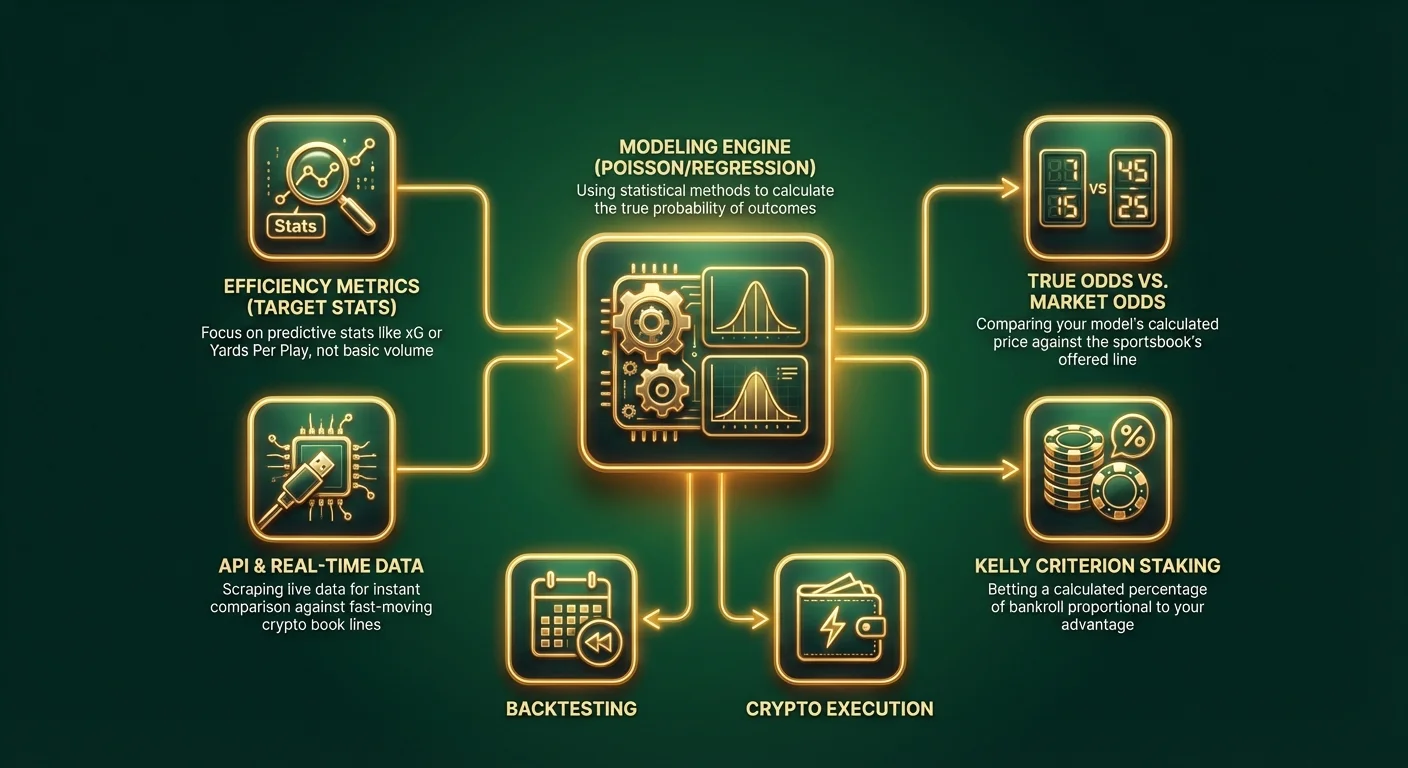
Trin 1: Definition af Omfang og Valg af Variable
Forsøg ikke at bygge en "Sports Betting Model", der dækker alt. Start i det små. Vælg én sport og ét specifikt marked.
Anbefalede Startpunkter:
- NBA Totaler: Højt volumen af scoringsbegivenheder reducerer varians sammenlignet med sportsgrene med lav scoring.
- NFL Spreads: Meget likvide markeder, omend meget effektive (svære at slå).
- Fodbold 1X2 (Moneyline): Fantastisk til statistisk modellering på grund af målscoringens Poisson-fordelingskarakter.
Feature Engineering (Valg af Dine Metrikker)
Garbage in, garbage out. Kvaliteten af din model afhænger udelukkende af de data, du fodrer den med. Undgå basale statistikker som "Sejre/Tab" eller "Point Pr. Kamp," da disse allerede er indregnet i enhver linje. Kig efter prædiktive metrikker – statistikker, der korrelerer stærkt med fremtidig præstation.
| Sport | Grundlæggende Statistik (Undgå) | Avanceret Statistik (Mål) | Hvorfor? |
|---|---|---|---|
| NBA | Points Pr. Kamp | Offensive Efficiency (ORtg) / Pace | Tager højde for spillets hastighed; et hurtigt hold scorer mere, men er ikke nødvendigvis bedre. |
| NFL | Total Yards | Yards Per Play / DVOA | Volumen-statistikker er misvisende; effektivitet pr. 'snap' forudsiger fremtidig succes bedre. |
| Fodbold | Scorede Mål | Expected Goals (xG) | xG måler kvaliteten af skabte chancer, hvilket er mere prædiktivt end heldige afslutninger. |
| MLB | Pitcher Wins | FIP (Fielding Independent Pitching) | Isolerer pitcherens præstation fra forsvaret bag ham. |
Pro Tip: Hvis du better med Bitcoin eller stablecoins på moderne krypto sportsbooks, har du ofte adgang til API-integrationer. Erfarne bettere bruger scripts til at scrape realtidsdata og øjeblikkeligt sammenligne dem med oddsene på hurtigt bevægelige kryptoplatforme.
Trin 2: Valg af Din Modelleringsmetode
Der er tre primære begyndermetoder til at bygge en prædiktiv model.
1. Power Ranking Modellen (Simpel)
Denne tildeler en numerisk vurdering til hvert hold. Forskellen mellem de to vurderinger, plus en justering for hjemmebanefordel, skaber spreadet.
- Eksempel: Hold A (Rating 105) mod Hold B (Rating 98) på en neutral bane antyder, at Hold A er en 7-points favorit.
2. Regressionsanalyse (Middel)
Denne bruger historiske data til at finde sammenhænge mellem variabler og udfald. Du kan køre en lineær regression for at se, hvordan "Passing Yards per Attempt" og "Turnover Differential" korrelerer med den endelige pointmargin.
- Værktøj: Microsoft Excel (Data Analysis Toolpak) eller Google Sheets.
3. Poisson-fordeling (Avanceret)
Ideel til sportsgrene med lav scoring som Fodbold eller Hockey. Den beregner sandsynligheden for, at et specifikt antal uafhængige begivenheder (mål) sker inden for et fastsat tidsrum.
- Koncept: Hvis et hold i gennemsnit scorer 1,5 mål pr. kamp, kan Poisson-matematik fortælle dig præcis, hvor sandsynligt det er, at de scorer 0, 1, 2 eller 3 mål i den næste kamp.
Trin 3: Bygning af en Simpel Poisson-model til Fodbold
Lad os gennemgå et praktisk eksempel på at bygge en model til at forudsige en Premier League-kamp ved hjælp af Poisson-fordelingen. Dette kan gøres udelukkende i et regneark.
Fase A: Beregn Angrebs- og Forsvarsstyrke
Du skal bestemme, hvor meget bedre eller dårligere et hold er sammenlignet med ligaens gennemsnit.
- Liga Gennemsnit: Beregn de gennemsnitlige mål scoret pr. kamp af et Hjemmehold og et Udehold på tværs af hele ligaen. (f.eks. Hjemme Gns. = 1,5, Ude Gns. = 1,2).
- Holdets Angrebsstyrke: Divider holdets gennemsnitlige scorede mål med Ligaens gennemsnit.
- Holdets Forsvarsstyrke: Divider holdets gennemsnitlige indkasserede mål med Ligaens gennemsnit.
Fase B: Forudsig Forventede Mål (xG)
For at finde ud af, hvor mange mål Hold A (Hjemme) sandsynligvis vil score mod Hold B (Ude), skal du bruge denne formel:
- Eksempel:
- Manchester City Angrebsstyrke: 1,8 (Meget stærk)
- Chelsea Forsvarsstyrke: 0,9 (Bedre end gennemsnittet)
- Liga Gennemsnit Hjemme Mål: 1,5
- Forudsagte City Mål:
Gentag dette for Udeholdet for at få deres forudsagte mål total.
Fase C: Konverter til Sandsynligheder
Nu hvor du har de forudsagte scorer (f.eks. City 2,43 - Chelsea 0,85), bruger du Poisson-funktionen (tilgængelig i Excel som =POISSON.DIST) til at beregne den procentvise chance for hvert specifikt scoringsresultat (1-0, 2-0, 1-1 osv.).
Ved at summere alle scoringsresultater, hvor City vinder, får du deres Vindersandsynlighed.
Trin 4: Konvertering af Sandsynlighed til Odds
Dette er det mest kritiske skridt inden for sportsanalyse. Du skal omsætte din procentdel til en betting-linje for at sammenligne med bookmakeren.
Formlen:
Sammenligningen:
| Udfald | Din Models Sandsynlighed | Dine "Sande" Odds | Bookmaker Odds | Fordel (EV) | Handling |
|---|---|---|---|---|---|
| Man City Sejr | 65% | 1.54 | 1.45 | Negativ | Spring Over |
| Uafgjort | 20% | 5.00 | 4.50 | Negativ | Spring Over |
| Chelsea Sejr | 15% | 6.67 | 8.00 | Positiv | VÆD |
I dette scenarie, selvom din model mener, at City er den sandsynlige vinder, ligger værdien på Chelsea. Bookmakeren betaler 8.00 (7/1) for et udfald, som din matematik siger burde være 6.67. Over tusindvis af væddemål garanterer det profit at tage disse værdipositioner.
Trin 5: Backtesting og Optimering
Du har en model. Væd ikke rigtige penge endnu. Du skal udføre Out-of-Sample Test.
Hvis du byggede din model ved hjælp af data fra 2020-2023 sæsonerne, kan du ikke teste den på de samme sæsoner. Din model "kender" allerede disse resultater. Du skal teste den på 2024 sæsonen (eller et datasæt, den ikke har set) for at se, om den faktisk forudsiger fremtiden.
Almindelige Modelleringsfælder:
- Overfitting: At skabe en model, der perfekt forklarer fortiden, men fejler i fremtiden, fordi den stolede på støj/tilfældigheder snarere end et signal.
- Look-ahead Bias: Utilsigtet at inkludere data i din test, som ikke ville have været tilgængelige på tidspunktet for kampen (f.eks. at bruge statistikker for hele sæsonen til at forudsige en kamp i uge 2).
- Ignorering af Kontekst: En model kan ikke læse Twitter. Den ved ikke, at start Quarterbacken har influenza. Du skal manuelt justere for store ændringer i opstillingen.
Udførelse: Staking og Kryptofordele
Når din model er bevist at have en positiv ROI (Return on Investment) over en betydelig stikprøvestørrelse (mindst 500 væddemål), er det tid til at eksekvere.
Kelly Kriteriet
Væd ikke fladt. Brug en staking-strategi baseret på din fordel. Kelly Kriteriet foreslår, at du vædder en procentdel af din bankroll proportionalt med din fordel.
- Forenklet Kelly: (Decimal Odds * Sandsynlighed - 1) / (Decimal Odds - 1)
- Advarsel: Fuld Kelly er ustabil. De fleste professionelle better "Quarter Kelly" eller "Half Kelly" for at reducere varians.
Udnyttelse af Krypto Sportsbooks
Kvantitativ betting kræver effektivitet. Kryptobettingsider tilbyder klare fordele for modelbaserede bettere:
- API-adgang: Mange moderne kryptobøger giver mulighed for automatiseret betting via API, hvilket sikrer, at du fanger linjen i det sekund, din model identificerer værdi.
- Højere Grænser: I modsætning til bløde fiat-bøger, der hurtigt begrænser vindere, tolererer high-volume krypto-exchanges og 'sharps' ofte vindende spillere, fordi de hjælper med at forme markedseffektiviteten.
- Øjeblikkelig Afregning: Når man kører en high-volume model, er cash flow altafgørende. Øjeblikkelige Bitcoin eller USDT udbetalinger betyder, at du kan genbruge din bankroll hurtigere, hvilket sammensætter din fordel dagligt snarere end ugentligt.
Praktiske Tips til Din Første Model
- Start med "Legetøjsmodeller": Forsøg ikke at slå NFL 'closing line' med det samme. Prøv at modellere noget mindre, som 1. quarters point eller 'player props'. Disse markeder er mindre effektive.
- Spor "CLV": Closing Line Value er guldstandarden for modellering. Hvis du vædder Chiefs til -3, og linjen lukker ved -4.5, virker din model, selvom Chiefs taber kampen. Konsekvent at slå 'closing line' er den sikreste indikator for langsigtet profitabilitet.
- Lær Python eller R: Selvom Excel er fantastisk til at lære, vil du på et tidspunkt ramme en mur med databehandling. Python (med biblioteker som Pandas og Scikit-learn) er industristandarden for sportsanalyse.
- Skrab Dine Egne Data: Stol ikke på gennemsnit, der findes på hjemmesider. Byg 'scrapers' for at få play-by-play data. Jo mere detaljerede dine data er, desto mere unik bliver din fordel.
Opsummering
At bygge en prædiktiv model er ikke en 'bliv rig hurtigt'-plan. Det er et datavidenskabsprojekt, der kræver tålmodighed, statistisk forståelse og stringent disciplin.
- Definer dit mål: Vælg en specifik sport og et marked.
- Indsaml data: Fokusér på prædiktive effektivitetsmetrikker, ikke volumen-statistikker.
- Byg motoren: Brug Regression eller Poisson-fordeling til at beregne sandsynligheder.
- Sammenlign odds: Konverter sandsynligheder til priser og find uoverensstemmelser på markedet.
- Backtest: Bevis, at modellen virker på usete data.
- Eksekver: Brug krypto sportsbooks for de bedste odds og hurtig likviditet.
Når du holder op med at bekymre dig om, hvilket hold der vinder, og begynder at bekymre dig om forskellen mellem implicit sandsynlighed og sand sandsynlighed, er du officielt gået fra at være en gambler til en sportsinvestor.