
Pro drtivou většinu sportovních sázkařů je uzavření sázky aktem intuice. Jde o rozhodnutí poháněné příběhy, fanouškovstvím nebo „pocitem v břiše“ odvozeným ze sledování posledních několika zápasů. I když takový přístup může občas přinést výhru, je matematicky nemožné porazit sázkové kanceláře dlouhodobě pouze na základě intuice. Marže sázkové kanceláře neboli 'vig' je navržena tak, aby v průběhu času rozdrtila subjektivní rozhodování.
Abyste přešli z rekreačního sázkaře k ziskovému „sharp“, musíte přestat hádat a začít počítat. To znamená, že přestanete sázet na týmy a začnete sázet na čísla.
Tento průvodce vás uvede do světa prediktivního modelování. Odstraníme závislost na mediálních narativech a zaměříme se na vybudování kvantitativního motoru, který generuje vlastní sázkové kurzy. Porovnáním „skutečných kurzů“ vašeho modelu s kurzy nabízenými krypto sázkovými kancelářemi můžete identifikovat pozitivní očekávanou hodnotu (+EV) a zajistit si matematickou výhodu.

Filozofie modelu: Cena vs. Výsledek
Než otevřete Excel nebo napíšete řádek kódu v Pythonu, musíte změnit své myšlení ohledně cíle sázení.
Častou chybou nováčků je ptát se: "Kdo vyhraje zápas?" Prediktivní model na tuto otázku neodpovídá přímo. Místo toho odpovídá: "Jaká je pravděpodobnost, že tento tým vyhraje?"
Pokud váš model určí, že Kansas City Chiefs mají 60% šanci na výhru, ale kurzy sázkové kanceláře implikují 70% šanci, nesázíte na Chiefs, i když si myslíte, že vyhrají. Naopak, pokud sázková kancelář implikuje 40% šanci, stávají se Chiefs obrovskou sázkou s hodnotou.
Proč sázení založené na datech funguje
Sázkové kanceláře jsou efektivní, ale nejsou dokonalé. Musí vyvažovat své knihy, aby zmírnily riziko, a často upravují kurzy na základě veřejného mínění. Robustní model tyto neefektivnosti využívá.
- Objektivita: Modely ignorují humbuk. Nezajímá je, zda se od hvězdného hráče „očekává“ velký zápas, pokud to data nepodporují.
- Škálovatelnost: Člověk dokáže hluboce analyzovat tři zápasy za hodinu. Model dokáže analyzovat 300 zápasů za tři sekundy.
- Disciplína: Modely poskytují pevný rámec pro sázky, čímž zabraňují emocionálnímu „tiltu“, který ničí bankrolly.
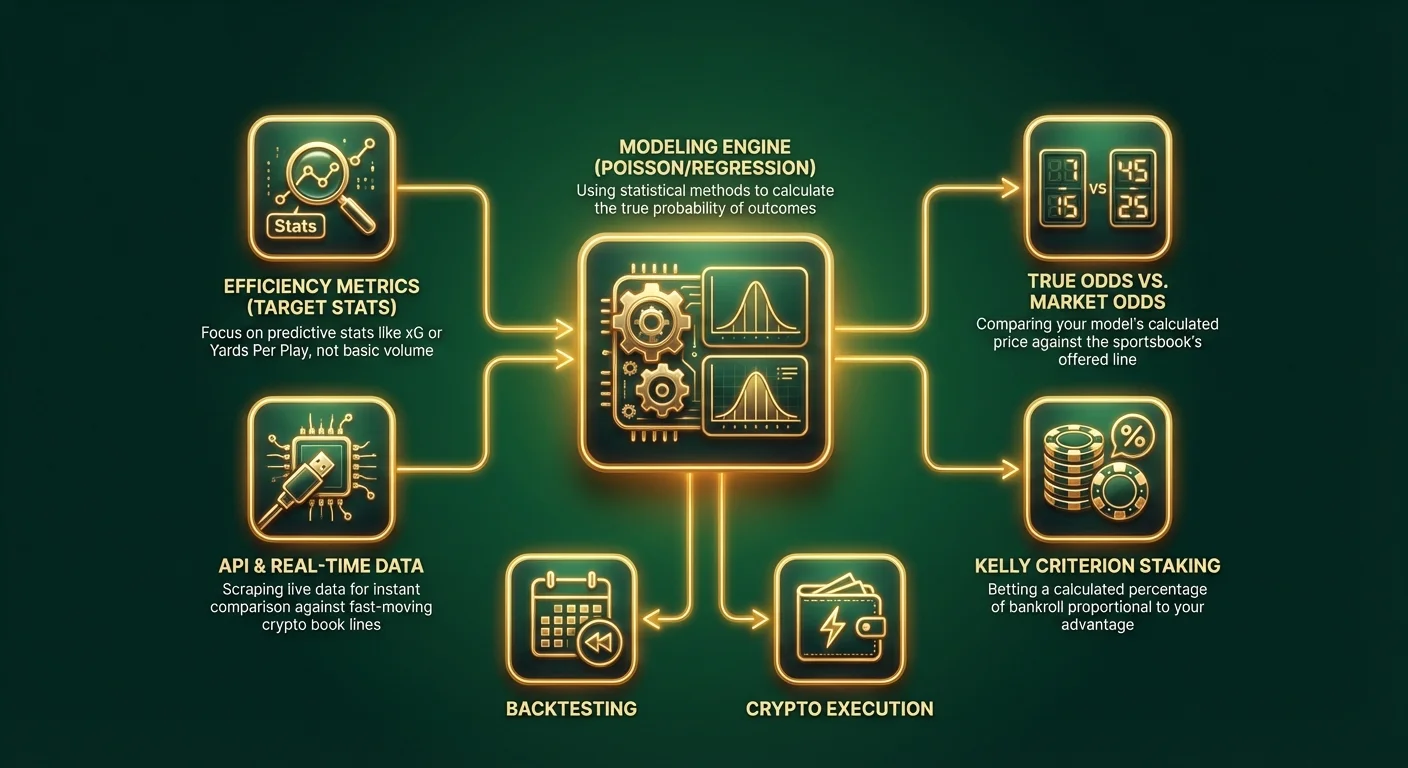
Krok 1: Definování rozsahu a výběr proměnných
Nesnažte se postavit "Model sportovního sázení", který pokrývá vše. Začněte v malém. Vyberte si jeden sport a jeden specifický trh.
Doporučené počáteční body:
- NBA Totals (Součty bodů): Vysoký objem bodových událostí snižuje varianci ve srovnání s nízko-bodovacími sporty.
- NFL Spreads (Handicapy): Vysoce likvidní trhy, i když velmi efektivní (těžko porazitelné).
- Soccer 1X2 (Moneyline): Skvělé pro statistické modelování díky povaze střílení gólů, která se řídí Poissonovým rozdělením.
Feature Engineering (Výběr metrik)
Co se do modelu dostane (garbage in), to z něj i vyjde (garbage out). Kvalita vašeho modelu zcela závisí na datech, která mu dodáte. Vyhněte se základním statistikám, jako jsou „Výhry/Prohry“ nebo „Body na zápas“, protože ty jsou již zohledněny v každém kurzu. Hledejte prediktivní metriky – statistiky, které silně korelují s budoucí výkonností.
| Sport | Základní statistika (Vyhněte se) | Pokročilá statistika (Zaměřte se) | Proč? |
|---|---|---|---|
| NBA | Points Per Game (Body na zápas) | Offensive Efficiency (ORtg) / Pace | Zohledňuje rychlost hry; rychlý tým skóruje více, ale nemusí být nutně lepší. |
| NFL | Total Yards (Celkové yardy) | Yards Per Play / DVOA | Objemové statistiky jsou zavádějící; efektivita na "snap" lépe předpovídá budoucí úspěch. |
| Soccer | Goals Scored (Vstřelené góly) | Expected Goals (xG) | xG měří kvalitu vytvořených šancí, což je prediktivnější než šťastné dokončení akcí. |
| MLB | Pitcher Wins (Výhry nadhazovače) | FIP (Fielding Independent Pitching) | Izoluje výkon nadhazovače od obrany za ním. |
Pro Tip: Pokud sázíte Bitcoinem nebo stablecoiny na moderních krypto sázkových kancelářích, často máte přístup k API integracím. Zkušení sázkaři používají skripty ke stahování dat v reálném čase a jejich okamžitému porovnání s kurzy na rychle se pohybujících krypto platformách.
Krok 2: Volba metody modelování
Existují tři primární metody pro začátečníky, jak postavit prediktivní model.
1. Model hodnocení síly (Power Ranking Model - Jednoduchý)
Tato metoda přiřazuje každému týmu číselné hodnocení. Rozdíl mezi těmito dvěma hodnoceními, plus úprava pro výhodu domácího hřiště, vytvoří spread (handicap).
- Příklad: Tým A (Hodnocení 105) vs. Tým B (Hodnocení 98) na neutrálním hřišti implikuje, že Tým A je favoritem o 7 bodů.
2. Regresní analýza (Regression Analysis - Středně pokročilá)
Využívá historická data k nalezení korelací mezi proměnnými a výsledky. Můžete spustit lineární regresi, abyste zjistili, jak "Passing Yards per Attempt" a "Turnover Differential" korelují s konečným bodovým rozdílem.
- Nástroj: Microsoft Excel (Data Analysis Toolpak) nebo Google Sheets.
3. Poissonovo rozdělení (Poisson Distribution - Pokročilé)
Ideální pro nízko-bodovací sporty, jako je fotbal nebo hokej. Počítá pravděpodobnost, že se v pevném čase uskuteční určitý počet nezávislých událostí (gólů).
- Koncept: Pokud tým průměrně vstřelí 1,5 gólu na zápas, Poissonova matematika vám přesně řekne, jaká je pravděpodobnost, že v příštím zápase vstřelí 0, 1, 2 nebo 3 góly.
Krok 3: Vytvoření jednoduchého Poissonova modelu pro fotbal
Pojďme si projít praktický příklad vytvoření modelu pro předpověď zápasu Premier League pomocí Poissonova rozdělení. To lze provést celé v tabulkovém procesoru.
Fáze A: Výpočet síly útoku a obrany
Musíte určit, o kolik je tým lepší nebo horší ve srovnání s ligovým průměrem.
- Ligový průměr: Vypočítejte průměrný počet vstřelených gólů na zápas domácím a hostujícím týmem napříč celou ligou. (např. Průměr Domácí = 1.5, Průměr Hosté = 1.2).
- Síla útoku týmu: Vydělte průměrné góly týmu ligovým průměrem.
- Síla obrany týmu: Vydělte průměrné inkasované góly týmu ligovým průměrem.
Fáze B: Predikce očekávaných gólů (xG)
Chcete-li zjistit, kolik gólů pravděpodobně vstřelí Tým A (Domácí) proti Týmu B (Hosté), použijte tento vzorec:
- Příklad:
- Síla útoku Manchester City: 1.8 (Velmi silná)
- Síla obrany Chelsea: 0.9 (Lepší než průměr)
- Ligový průměr domácích gólů: 1.5
- Předpokládané góly City:
Opakujte to pro hostující tým, abyste získali jejich předpokládaný celkový počet gólů.
Fáze C: Převod na pravděpodobnosti
Nyní, když máte předpokládané skóre (např. City 2.43 - Chelsea 0.85), použijte Poissonovu funkci (dostupnou v Excelu jako =POISSON.DIST) k výpočtu procentuální šance každého konkrétního skóre (1-0, 2-0, 1-1 atd.).
Sečtením všech skóre, při kterých City vyhrává, získáte jejich pravděpodobnost výhry.
Krok 4: Převod pravděpodobnosti na kurzy
Toto je nejdůležitější krok ve sportovní analytice. Musíte přeložit své procento do sázkového kurzu, abyste jej mohli porovnat se sázkovou kanceláří.
Vzorec:
Porovnání:
| Výsledek | Pravděpodobnost dle Vašeho modelu | Váš "Skutečný" Kurz | Kurz sázkové kanceláře | Výhoda (EV) | Akce |
|---|---|---|---|---|---|
| Výhra Man City | 65% | 1.54 | 1.45 | Negativní | Vynechat |
| Remíza | 20% | 5.00 | 4.50 | Negativní | Vynechat |
| Výhra Chelsea | 15% | 6.67 | 8.00 | Pozitivní | SÁZET |
V tomto scénáři, i když si váš model myslí, že City je pravděpodobným vítězem, hodnota je na Chelsea. Sázková kancelář platí 8.00 (7/1) za výsledek, který by podle vaší matematiky měl být 6.67. Při tisících sázek zajišťuje přijímání těchto pozic s hodnotou zisk.
Krok 5: Backtesting a optimalizace
Máte model. Zatím nesázejte skutečné peníze. Musíte provést testování mimo vzorek (Out-of-Sample Testing).
Pokud jste model postavili s použitím dat ze sezón 2020–2023, nemůžete ho testovat na stejných sezónách. Váš model již tyto výsledky „zná“. Musíte ho otestovat na sezóně 2024 (nebo na datové sadě, kterou neviděl), abyste zjistili, zda skutečně předpovídá budoucnost.
Časté chyby modelování:
- Overfitting (Přeučení modelu): Vytvoření modelu, který dokonale vysvětluje minulost, ale selhává v budoucnosti, protože se spoléhal spíše na „šum“/náhodu než na signál.
- Look-ahead Bias (Zkreslení dopředu): Neúmyslné zahrnutí dat do testu, která by v době hry nebyla dostupná (např. použití statistik za celou sezónu k predikci zápasu 2. týdne).
- Ignorování kontextu: Model neumí číst Twitter. Neví, že startující Quarterback má chřipku. Musíte ručně upravit model pro velké změny v sestavě.
Exekuce: Staking a výhody krypta
Jakmile se prokáže, že váš model má pozitivní ROI (Return on Investment) na významném vzorku (alespoň 500 sázek), je čas na exekuci.
Kellyho kritérium
Nesázejte vždy stejnou částku (flat bet). Použijte strategii sázení založenou na vaší výhodě. Kellyho kritérium navrhuje sázet procento vašeho bankrollu úměrné vaší výhodě.
- Zjednodušené Kellyho kritérium: (Desetinný Kurz * Pravděpodobnost - 1) / (Desetinný Kurz - 1)
- Varování: Plné Kellyho kritérium je volatilní. Většina profesionálů sází "Quarter Kelly" nebo "Half Kelly", aby snížila varianci.
Využití krypto sázkových kanceláří
Kvantitativní sázení vyžaduje efektivitu. Krypto sázkové stránky nabízejí výrazné výhody pro sázkaře založené na modelech:
- Přístup k API: Mnoho moderních krypto sázkových kanceláří umožňuje automatizované sázení přes API, což zajišťuje, že zachytíte kurz v okamžiku, kdy váš model identifikuje hodnotu.
- Vyšší limity: Na rozdíl od "soft" fiat sázkových kanceláří, které rychle omezují vítězné hráče, high-volume krypto burzy a "sharps" často tolerují vítězné sázkaře, protože pomáhají utvářet tržní efektivitu.
- Okamžité vypořádání: Při provozování high-volume modelu je cash flow klíčové. Okamžité výběry v Bitcoinu nebo USDT znamenají, že můžete svůj bankroll cyklovat rychleji a složitě úročit svou výhodu denně, nikoli týdně.
Praktické tipy pro váš první model
- Začněte s "Testovacími" modely: Nesnažte se okamžitě porazit závěrečný kurz NFL. Zkuste modelovat něco menšího, jako jsou body za 1. čtvrtinu nebo "player props". Tyto trhy jsou méně efektivní.
- Sledujte "CLV": Closing Line Value (hodnota závěrečného kurzu) je zlatý standard modelování. Pokud vsadíte na Chiefs při -3 a kurz se uzavře na -4.5, váš model funguje, i když Chiefs zápas prohrají. Důsledné překonávání závěrečného kurzu je nejjistějším ukazatelem dlouhodobé ziskovosti.
- Naučte se Python nebo R: Zatímco Excel je skvělý pro učení, nakonec narazíte na zeď při zpracování dat. Python (s knihovnami jako Pandas a Scikit-learn) je průmyslovým standardem pro sportovní analytiku.
- Stahujte si vlastní data: Nespoléhejte se na průměry nalezené na webových stránkách. Vytvořte si scrapovací skripty pro získání dat "play-by-play". Čím detailnější jsou vaše data, tím unikátnější bude vaše výhoda.
Shrnutí
Vytvoření prediktivního modelu není způsob, jak rychle zbohatnout. Je to projekt v oblasti datové vědy, který vyžaduje trpělivost, statistickou gramotnost a přísnou disciplínu.
- Definujte svůj cíl: Vyberte si konkrétní sport a trh.
- Sbírejte data: Zaměřte se na prediktivní metriky efektivity, nikoli na objemové statistiky.
- Sestavte motor: Použijte regresi nebo Poissonovo rozdělení k výpočtu pravděpodobností.
- Porovnejte kurzy: Přeměňte pravděpodobnosti na ceny a najděte nesrovnalosti na trhu.
- Backtestujte: Dokažte, že model funguje na neviděných datech.
- Realizujte: Použijte krypto sázkové kanceláře pro nejlepší kurzy a rychlou likviditu.
Když se přestanete starat o to, který tým vyhraje, a začnete se starat o rozdíl mezi implikovanou a skutečnou pravděpodobností, oficiálně jste se z hazardního hráče stali sportovním investorem.